俗话说“工欲善其事,必先利其器”。深度学习环境可以被视为深度学习任务的基础设施,是进行深度学习研究、开发和部署的利器。然而,初学者在面对配置深度学习环境中繁杂的深度学习框架、函数库、调试工具等时,往往一头雾水、手足无措。深度学习环境配置成了众多初学者的第一个拦路虎。因此,一个简便、快速、完善的深度学习环境配置将极大的降低初学者的入门成本,并为后续的深度学习项目开发奠定良好的基础。本章将介绍基于Docker的深度学习环境配置方式,包括驱动以及软件的安装和使用、软件之间的扩展等。才外,本章还将介绍在深度学习任务开始之前的数据集的准备过程,包括常用数据集的介绍、数据增强方法以及如何自作自己的数据集等。
2.1 深度学习环境的配置
在配置深度学习环境之前,首先需要思考一个问题:什么样的环境才是简洁、便利、高效的深度学习环境呢?笔者认为,一个良好的深度学习环境需要具备三个特点:1、能够快速安装;2、不同版本之间不冲突;3、能够避免反复重装系统。许多读者应该对最后一个特点能够产生共鸣。许多研究者在入门深度学习时可能都或多或少的经历过这样的事情:由于某个库的安装失败、或者某个库的错误删除,导致最后不得不重新安装系统。在本书中,笔者推荐采用Ubuntu+Docker+VSCode的深度学习环境配置方法。这个方法不仅可以以七步快速完成深度学习环境配置,而且能够避免不同版本之间的冲突。接下来,将详细的介绍如何通过“七步法”快速、高效的配置深度学习环境。
2.1.1 安装显卡驱动
显卡(GPU)是进行深度学习任务的必备硬件之一。目前,深度学习领域常用的显卡为英伟达(NIVDIA)公司研发的产品。为了使程序能够在GPU上执行,英伟达公司发开CUDA框架。CUDA 最初被设计用于加速通用计算任务,特别是在深度学习任务中,得到了广泛的应用。此外,众多深度学习框架,如TensorFlow、PyTorch等,都基于CUDA编写GPU加速代码,以在英伟达的显卡上运行,提高训练和推理速度。英伟达提供的显卡驱动程序(包括支持 CUDA 的驱动)是确保 CUDA 在 GPU 上正常运行的重要组成部分。因此,在安装深度学习框架之前必须安装显卡驱动。
Ubuntu系统是研究人员进行深度学习任务的主流操作系统。而随着Ubuntu系统的逐渐升级,已经将安装显卡驱动的环境集成在了系统安装过程中。在安装Ubuntu系统时,读者需要在连接网络的前提下,一定要选择“下载第三方安装包”这一项。由于Ubuntu系统的安装过程比较简单,也不是本书的重点,读者可以通过网络资料,或者通过本书提供的GitHub库找到相关教程。Ubuntu系统安装完成后,在左边左上角的搜索处搜索并打开“软件和更新”,可以看到如图2-1所示的页面。
 在页面中,选择“附加驱动”选项,便可以看到系统中已经带有的NVIDIA驱动。选择合适的驱动后,点击页面下方的“应用更改”,等到一段时间后,系统变安装选择的版本的驱动。为了验证系统是否成功安装显卡驱动,可以通过指令2-1中的命令来查看显卡当前的状态。
在页面中,选择“附加驱动”选项,便可以看到系统中已经带有的NVIDIA驱动。选择合适的驱动后,点击页面下方的“应用更改”,等到一段时间后,系统变安装选择的版本的驱动。为了验证系统是否成功安装显卡驱动,可以通过指令2-1中的命令来查看显卡当前的状态。
指令2-1
1.nvidia-smi
当系统成功安装显卡驱动后,便可以看到如图2-2所示的信息。指令2-1中的命令是深度学习开发中常用的命令之一。通过该命令,可以查看当前显卡的运行状态,例如当前计算机装有显卡数量、每个显卡的型号、显存大小、安装的驱动的版本等。从图2-2中的信息可以看出,当前的计算机安装了两张RTX 3060的显卡,每张显卡具有12288M的显存。目前0号显卡显存的使用量为748M。此外,还可以看出,当前计算机安装的显卡驱动版本为535.129.03,推荐安装的CUDA版本为12.2。
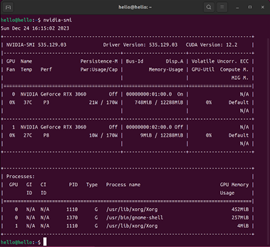 当我们看到图2-2所示的结果时,便完成了“七步安装法”的第一步。
当我们看到图2-2所示的结果时,便完成了“七步安装法”的第一步。
2.1.2 安装Docker
Docker 是一种开源平台,用于轻松部署、管理和运行应用程序容器。Docker 的主要目标是通过容器化技术提供一种一致的部署和运行环境,使应用程序在不同的计算机上能够以相同的方式运行,消除了"在我的机器上能够工作"的问题。简单来说,可以将Docker理解成一个机房,在机房中可以放置多台电脑,并且可以在每台电脑安装不同的系统、软件、工程等。当机房中的某一台电脑损坏或者不再需要时,可以直接移除该电脑,而不影响其他电脑以及机房整体的使用。此外,在Docker中,可以将其他机房的电脑直接搬到自己的机房中使用,而不用担心无法工作的问题。在Docker的使用中,最常涉及到的概念有:镜像、容器、Dockerfile文件。其中,容器可以理解为机房中的电脑,镜像理解为安装在电脑上的系统,而Dockerfile文件则是用来自动创建镜像的文件。Docker允许创建多个容器,并且可以基于同一镜像快速创建多个容器。此外,也可以在容器内再次安装其他软件的方式,创建含有特定版本的函数库,例如,在两个不同的容器中分别安装Python 3.6和Python3.8,而不产生任何的冲突。
读者可以通过访问Docker官网找到在Ubuntu系统中安装Docker教程。目前,安装教程的链接为https://docs.docker.com/engine/install/ubuntu/。在教程中找到Install using the apt repository部分,按照教程中的1、2、3步骤顺序安装即可。具体过程如下:
1. 在安装过程中,首先需要配置Docker的资源库,这样系统便可以找到Docker,并进行安装。配置资源库的命令如指令2-2中所示:
指令2-2
1. sudo apt-get update
2. sudo apt-get install ca-certificates curl gnupg
3. sudo install -m 0755 -d /etc/apt/keyrings
4. curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
5. sudo chmod a+r /etc/apt/keyrings/docker.gpg
6. echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
7. sudo apt-get update
2. 配置资源库之后,可以通过指令2-3中的命令安装Docker与相关插件。
指令2-3
1. sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
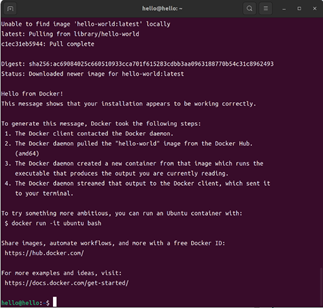
3. 最后,通过指令2-4中的命令验证是否成功安装Docker。成功安装之后,输入指令2-4中的命令后将会输出如图2-3所示的内容
指令2-4
1. sudo docker run hello-world
 > 注意:为了保持环境配置步骤的连贯性,关于Docker使用过程中常用的指令将在2.1.8节中单独介绍。
> 注意:为了保持环境配置步骤的连贯性,关于Docker使用过程中常用的指令将在2.1.8节中单独介绍。
2.1.3 添加Docker到用户组
在Docker安装之后,每次在终端通过命令操作Docker时,都需要获取root身份,导致体验感不佳。如果没有获得root身份,每次输入命令未加sudo时就会出现如图2-4中的结果。
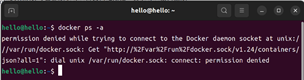 为了避免每次使用Docker时都需要输入密码获取root身份的繁琐操作,可以通过指令2-5中的指令将Docker添加到用户组中。
为了避免每次使用Docker时都需要输入密码获取root身份的繁琐操作,可以通过指令2-5中的指令将Docker添加到用户组中。
指令2-5
1. sudo usermod -aG docker
2. sudo chmod a+rw /var/run/docker.sock
3. sudo systemctl restart docker
4. docker ps -a
指令2-5中第1行里的为电脑的用户名,以图2-4中的账户为例,在运行第一行代码的时候替换为hello。依次执行完指令2-5中1到3行指令后,即完成将Docker添加到用户组的目的。在运行第4行命令之前,需要关闭终端,并打开一个新的终端。在新终端内输入第4行命令之后,输出入图2-5中所示的结果,表示将Docker添加到用户组成功。
 ### 2.1.4 安装NVIDIA Container Toolkit
### 2.1.4 安装NVIDIA Container Toolkit
由于需要在Docker的容器里面运行程序,因此需要安装NVIDIA Container Toolkit,来使Docker创建的容器具有调用英伟达驱动的能力。同样建议依照官网的教程安装该软件。目前,官网的链接为https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html。在安装时,只需要执行官网教程中Installing with Apt部分的1、2、3步。然后执行Configuring Docker部分的第1步和第2步。所有命令如指令2-6所示。
指令2-6
1. curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
2. sudo apt-get update
3. sudo apt-get install -y nvidia-container-toolkit
4. sudo nvidia-ctk runtime configure --runtime=docker
5. sudo systemctl restart docker
安装完成之后,需要安装能够沟通Docker与NVIDIA的nvidia-docker2插件。其安装方式如指令2-7中所示。
指令2-7
1. sudo apt-get install nvidia-docker2
2.1.5 创建Docker镜像与容器
到目前,所有的软件、库的安装步骤已经完成。接下来便是通过Dockerfile创建镜像,并基于镜像创建最终的容器。在创建Docker镜像之前,读者需要从本书引言部分的网络资源库中下载Dockerfile文件。Dockerfile文件中的内容如代码清单2-1中所示。如果读者不方便下载,也可以自行创建Dockerfile文件。
代码清单2-1
1. FROM nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04
2. ENV DEBIAN_FRONTEND=noninteractive
3. RUN apt-key del 7fa2af80
4. RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu 2004/x86_64/3bf 863cc.pub
5. RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu2004/x86_64/7fa2af80.pub
6. RUN apt-get update && apt-get install -y vim python3 python3-pip
7. RUN pip3 install --upgrade pip
8. RUN pip3 install setuptools>=40.3.0
9. RUN pip3 install -U scipy scikit-learn
10. RUN pip3 install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
11. RUN pip3 install torchsummary
12. RUN pip3 install tensorboard==2.11.0
代码清单2-1中的第一行表示构建基于 NVIDIA CUDA 11.3.1 和 cuDNN 8 开发环境的 Docker 镜像。其中FROM是Dockerfile 中的指令,用于指定基础镜像。nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04表示这是一个NVIDIA 提供的基于 Ubuntu 20.04 操作系统的 Docker 镜像,预装了 NVIDIA CUDA 11.3.1 和 cuDNN 8 开发环境。如果读者想安装其他版本的环境,需要去Docker Hub的官网查找自己需要的版本,并修改该行命令。需要注意的是,基础镜像都是由其他方提供的,因此读者一定需要去寻找指定的命令,而不能通过自行修改。
第二行的命令表示设置环境变量,以使得在安装软件包时不需要用户输入交互。
第三行的命令表示删除之前可能存在的旧的 apt-key,这是为了解决一些安全性问题。
第四行的命令表示下载并导入 NVIDIA CUDA 存储库的 GPG 密钥。
第五行的命令表示下载并导入 NVIDIA Machine Learning 存储库的 GPG 密钥。
第六行的命令表示更新 apt 软件包列表,然后安装 vim 编辑器、Python3 和 pip 等工具。从这行命令开始,就在为构建的镜像安装一些深度学习工具,例如安装scikit-learn、1.12.1版本的Pytorch、以及可视化工具tensorboard等。这些命令于Ubuntu系统中常规安装软件方式相同,这里不再重复赘述。
准备好Dockerfile之后,通过指令2-8中的命令创建Dockerfile中指定的镜像。需要注意的是,需要通过终端进入到Dockerfile文件所在的文件夹内运行指令2-8中的命令。由于该命令会检查文件夹中所有的文件,最终找到名为Dockerfile的文件。因此,建议读者重建一个新的文件夹用于存放单独的Dockerfile文件。
指令2-8
1. docker build -t docker_image_hello .
指令2-8中的命令将会创建一个名为docker_image_hello的镜像。该镜像里安装着Dockerfile文件中指定的软件。运行该命令时由于需要下载众多安装包,因此根据网速的差异可能需要等待较长时间。在安装过程中如果出现一些关于root权限的红色文字提示,可以忽略,不用关注。当Dockerfile中所有的命令运行完成之后,将成功创建镜像。之后,可以通过指令2-9中的命令查看本机已经创建完成的镜像。
指令2-9
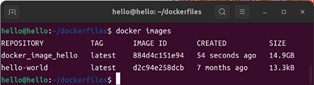
1. docker images
运行指令2-9中的命令后,终端将会输入如图2-6所示的内容。图2-6中的内容表示本机已经创建的镜像的相关信息,例如每个镜像的名字、ID以及时间、大小等。从图中可以看出,本机目前只有两个镜像,分别是指令2-4创建hello-world和指令2-8创建的docker_image_hello。
 创建镜像之后,就需要通过指令2-10中的命令将镜像安装在机房的电脑上,即创建一个名为docker_container_hello的容器。
创建镜像之后,就需要通过指令2-10中的命令将镜像安装在机房的电脑上,即创建一个名为docker_container_hello的容器。
指令2-10
1. docker run -it --shm-size 8G -p 1234:6006 --name docker_container_hello --gpus all -v ~/Hello:/workspace docker_image_hello
指令2-10中docker run表示运行Docker容器的命令,每个参数的含义如下所示:
-it表示,在交互式模式下运行容器。
-i 表示保持标准输入打开,-t 表示为容器分配一个伪终端。
–shm-size 8G表示设置容器中 /dev/shm 的大小为 8GB。这通常用于调整共享内存大小,某些应用可能需要较大的共享内存。
-p 1234:6006表示将容器内部的端口 6006 映射到主机上的端口 1234。这使得我们可以通过主机上的 localhost:1234 访问容器内运行的应用程序。可以调整主机上的端口来调整映射的端口。需要注意的是,主机上的一个端口号只能映射到一个容器。
–name docker_container_hello表示创建的容器名字为docker_container_hello。
–gpus all表示创建的容器可以使用所有的 GPU 设备。v /Hello:/workspace: 将主机上的 ~/Hello目录挂载到容器内的 /workspace 目录。这是一个容器内外的文件共享机制,使得容器内的文件可以在主机和容器之间共享。即,修改~/Hello里的文件,就可以直接修改容器内/workspace中的文件。
docker_image_hello表示使用名为docker_image_hello的镜像创建容器。
指令2-10中的命令运行成功之后,将会出现自动进入到创建的容器内,具体内容如图2-7所示。创建成功之后,可以使用通过exit命令退出容器。需要注意的是,在首次创建成功之后,通过exit退出容器之后,容器将会自动停止。如果再次需要进入容器,需要重新开启容器,并通过终端进入到容器中。但是,当重启之后再进入容器后,通过exit命令只会在终端退出容器,而不会停止容器。
注意:关于容器的使用方式将在2.1.8节单独介绍。因此为了保证后续的步骤能够正常进行,建议读者不要退出容器或者关闭容器的终端
 ### 2.1.6 测试深度学习项目
### 2.1.6 测试深度学习项目
成功创建容器后,已经完成了深度学习环境的配置。这意味着,读者已经可以在容器内进行深度学习项目的研发了。但是,我们将通过复现一个现有的深度学习项目来验证深度学习环境是否配置完成。读者首先需要从本书的网络资源库中下载复现深度学习项目的所有文件,并将全部文件放置到容器映射的文件夹内,即~/Hello文件夹里。所有文件的存放方式如图所示。之后,在容器的终端里通过cd workspace命令进入到容器空间内,然后通过ls命令查看能否看到这些文件。如果能够看到刚才放入的文件,则表明容器与本机实现文件的共享。之后,在/workspace目录内通过指令2-11中的命令运行程序。
指令2-11
1. python3 run_demo.py
运行程序后,能够看到终端不断地输出程序运行地信息,那么恭喜你,已经成功配置了深度学习环境,并且成功的复现了一个深度学习项目。该深度学习项目为分割交通场景中的正障碍物和负障碍物。本书的第七章将会详细介绍该深度学习项目。等待程序运行完成后,将会在文件夹内看到一个名为results的文件夹。里面存放的为网络对图像中的正障碍物和负障碍物的分割结果。读者可以对比dataset/left/文件夹中的图像和预测结果,来直观的比较网络分割结果的准确性。
2.1.7 Docker+VS Coder配置
通过前面的六个步骤已经完成了深度学习项目开发环境的配置。然而,目前仍然只能在终端界面进入Docker的镜像,并且只能在终端界面运行深度学习程序。对于许多习惯了通过界面化的编译器编写程序的读者来说,通过终端来编写和运行程序将是一个巨大的挑战。因此,接下来笔者将会介绍如何将VS Code软件与Docker结合,实现一个界面化的深度学习开发环境。
读者首先需要在软件中心搜索并安装VS Code软件。安装完成后,首次打开VS Code软件后需要安装三个扩展插件:docker,docker compose和dev containers,以实现在VS Coder中进入Docker的目的。安装插件之后,通过软件界面的左上角的file(文件)标签选择New Open Folder(打开文件夹)选项,打开上一节中下载的Hello文件夹。打开后会在界面左上角找到一个名为.devcontainer的文件夹。该文件夹是通过VS Coder创建新容器、进入已有容器的关键。文件夹内有两个名为decontainer.json和docker-compose.yml的两个文件。两个文件的内容分别如代码清单2-2和代码清单2-3所示。通过调整两个文件中的内容,即可调整VS Code创建的容器的名称和进入哪个容器。
注意:该文件夹通过电脑的文件管理系统在Hello文件夹里无法看到。原因是,当文件夹的名字前面有个.时,系统会自动隐藏该文件夹。此时,通过快捷键Ctrl+H便可以在文件夹内看到.devcontainer文件夹。
decontainer.json文件定义了容器的名字。读者可以自由设置name的值调整创建或者进入的容器的名字。代码清单2-2中第4行的service的值需要与代码清单2-3行中第4行的值相同。笔者建议,将两者都设置成与代码清单2-2第2行相同的值。建议读者只调整decontainer.json文件中第2行和第4行的内容,其余内容保持不变。docker-compose.yml文件中,建议读者只调整第4、6、8、15行的内容。docker-compose.yml文件中的第6行表示创建容器时使用的镜像。作者需要选择一个已经在电脑中创建的镜像。第8行内容为创建容器时使用的端口号,同样也要求该端口号不被使用。第15行的内容表示创建的容器能够调用的显卡的序号。如果读者的电脑只有一张显卡,则需要注释或者删除第15行内容。如果拥有更多的显卡,则需要读者添加其他显卡的序号,才能在创建的容器中使用其他显卡。通常来讲,显卡的需要从0开始编号。例如,如果有4张显卡,则需要再添加- /dev/nvidia2和- /dev/nvidia3两行命令。
代码清单2-2 decontainer.json文件中的内容
1. {
2. "name": "newHello",
3. "dockerComposeFile": "docker-compose.yml",
4. "service": "newHello",
5. "workspaceFolder": "/workspace"
6. }
代码清单2-3 docker-compose.yml文件中的内容
1. {
2. version: '2.3'
3. services:
4. newHello:
5. runtime: nvidia
6. image: docker_image_hello
7. ports:
8. - '11602:6006'
9. volumes:
10. - ..:/workspace:cached # Do not change!
11. - /var/run/docker.sock:/var/run/docker-host.sock
12. shm_size: 32g
13. devices:
14. - /dev/nvidia0
15. - /dev/nvidia1
16. command: sleep infinity
17. }
设置完成两个文件后,点击VS Coder界面左下角“><”图标,在跳出的界面中选择Reopen in Container,等待一段时间之后,就可以创建并进入容器。之后,点击左上方Terminal选项,便可以在VS Code界面的中下方打开一个终端。此时可以看到,终端里直接进入了workspace目录内。在界面的左侧,可以看到Hello文件夹内的所有文件。在终端内输入指令2-10中的命令,便可以看到程序的运行。在VS Code所有的操作都等同于在2.1.6节中在终端的操作。
注意:在VS Code创建的所有文件都需要root权限在可以在文件夹中修改,因此建议读者在文件夹界面创建文件的方式来增加内容,而不是直接在VS Code软件内创建。
读者通过上述的七个步骤应该已经掌握了深度学习开发环境和开发软件的配置过程。接下来就可以开始真正的深度学习项目的学习,并通过代码实现自己的想法了。
2.1.8 使用Docker常用命令
本小节将介绍在深度学习项目开发过程中常用的Docker操作命令。如果读者之前使用过Docker可以直接跳过本小节的内容。读者也可以将本小节的内容当作查询手册,当需要的时候,来查找相关的命令代码。
指令2-12
1. docker info
2. docker ps
3. docker ps -a
4. docker rm docker_container _hello
5. docker images
6. docker rmi docker_image_hello
7. docker start docker_container_hello
8. docker stop docker_container_hello
9. docker restart docker_container_hello
10. docker exec -it docker_container_hello /bin/bash
指令2-12中每一行命令的含义如下:
第1行命令表示输出当前安装的docker软件的详细信息。
第2行命令表示输出所有正在运行的容器
第3行命令表示输出所有的容器,包括正在运行、已经关闭、创建失败的容器等。
第4行命令表示删除名为docker_container_hello的已经关闭的容器。如果容器未关闭,需要先关闭容器后才能删除容器
第5行命令表示输出所有的镜像
第6行命令表示删除名为docker_image_hello的镜像
第7行命令表示开启名为docker_container_hello的容器
第8行命令表示关闭名为docker_container_hello的容器
第9行命令表示重启名为docker_container_hello的容器
第10行命令表示在当前终端进入到名为docker_container_hello的容器中。


🚀 深度学习环境配置指南:从零到一,轻松上手! 🚀
你是否在为配置深度学习环境而头疼?🤯 别担心!我们为你准备了一份超详细的教程,帮助你快速搭建一个高效、稳定的深度学习开发环境!
🔧 核心工具:
📌 七步搞定深度学习环境:
1️⃣ 安装显卡驱动
2️⃣ 安装Docker
3️⃣ 添加Docker到用户组
4️⃣ 安装NVIDIA Container Toolkit
5️⃣ 创建Docker镜像与容器
6️⃣ 测试深度学习项目
7️⃣ 配置Docker+VS Code
💡 为什么选择Docker?
🎯 适合人群:
📚 更多内容:
👉 立即开始你的深度学习之旅!
点击链接,获取完整教程:[文章链接]
#深度学习 #Docker #环境配置 #VSCode #Ubuntu #AI开发