本文介绍了如何使用 OpenAI 官方提供的 API 部署 ChatGPT,并以企业微信机器人为例,快速实现自然语言理解和生成功能。
本文还对官方文档提供的模型和 ChatGPT 使用的模型进行了比较,并提供了使用 golang、python、PHP 和 nodejs 等常见语言请求 ChatGPT 的代码。本文会大致说一下基于企业微信、飞书、钉钉等工具自建的机器人的相关流程,其中企业微信机器人的代码可以参考项目:https://github.com/thlz998/openai-bot
快速部署
先看看如何使用`docker一行代码运行OpenAI机器人(企业微信版本)
> docker run -d -p 3201:3200 \ -e api_key="[chatgpt的APIkey]" \ -e app_port=":3200" \ -e app_model="text-davinci-003" \ -e wework_token="[企业微信自建应用的API token]" \ -e wework_encodingAeskey="[企业微信自建应用的encodingAeskey]" \ -e wework_corpid="[企业微信企业唯一ID]" \ -e wework_secret="[企业微信自建应用的secret]" \ -e wework_agentid="[企业微信自建应用的agentid]" \ ibfpig/openai-wework:1.0.0# 记得把用中括号OpenAI的相关信息和企业微信的相关信息换成自己的,其中OpenAI的apikey可以直接访问这个链接来创建和获取:https://platform.openai.com/account/api-keys
如果觉得部署机器人麻烦,我们来看看最重要的是什么:
> curl -X "POST" "https://api.openai.com/v1/completions" \-H 'Authorization: Bearer [这里换成你的API key]' \-H 'Content-Type: application/json; charset=utf-8' \-d $'{"prompt": "你好","frequency_penalty": 0,"model": "text-davinci-003","temperature": 0.7,"presence_penalty": 0,"max_tokens": 2000,"top_p": 1}'# 记得把这一行代码中的api key换成自己的api key,可以直接访问这个链接来创建和获取:https://platform.openai.com/account/api-keys
## 机器人流程原理
我们部署的机器人大概得流程是这样的:
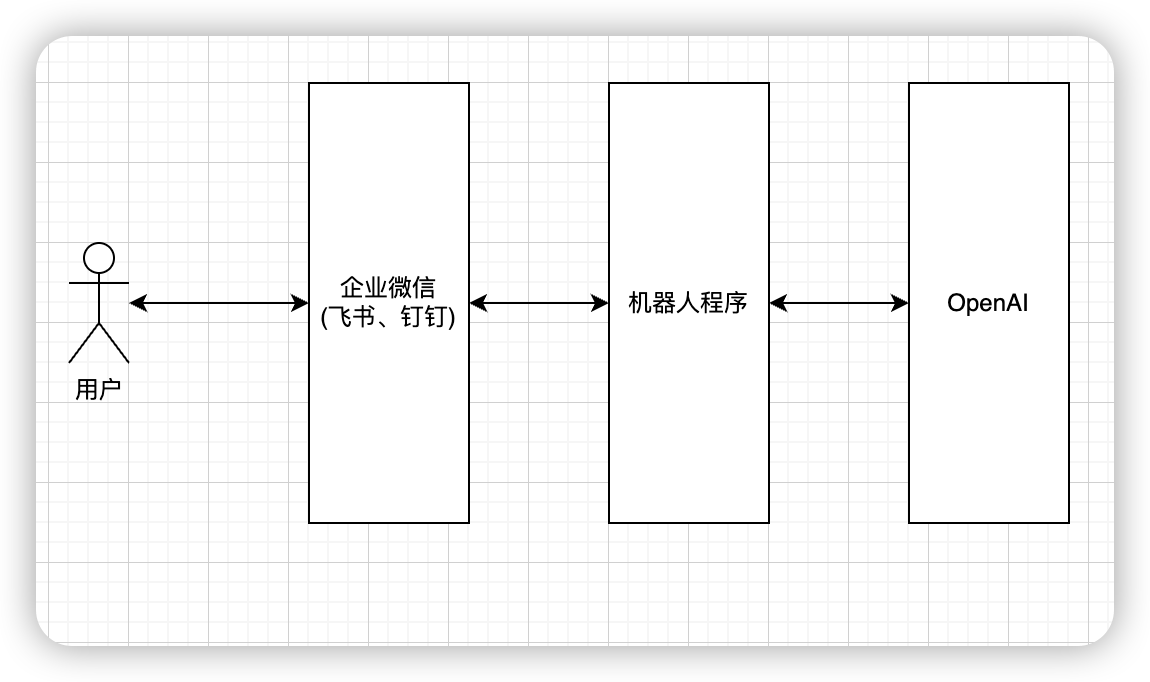
用户直接与企业微信自建应用聊天,之后企业微信会将收到的消息回调给我们写的机器人程序,我们拿到用户请求的内容去发给ChatGPT,等ChatGPT回复我们之后,我们再通过企业微信把消息发送给用户。
很好理解,其实就是以下三个步骤
1. 接收企业微信的应用消息
2. 发送请求给ChatGPT并拿到返回的内容
3. 通过企业微信给用户回复消息
## 如何自建企业微信应用
(钉钉飞书流程差不多,可以具体参考相关文档)
**新建企业微信应用**
1. 登录企业微信后台,在应用管理中,点击创建应用,设置好你的机器人的logo、名字,并选择可以使用机器人的企业微信用户
1. 查看Secret并记录下来
2. 设置企业可信IP,这个可信ip就是指能够给企业微信发送请求的服务器ip,需要是对外的公网ip,如果有服务器就填服务器的公网ip,如果在本地运行,就看看https://ip138.com 上写的地址是啥就填啥就可以了
3. 在接收消息这一栏点那一行设置API接受消息,URL填这个https://xxxx.com/api/wework,其中,Token和EncodingAESKey点随机获取就可以了,这个时候点保存肯定会提示不通过,我们先停在这个页面,然后开始编码。如果是在本地电脑上做调试,需要做好反向代理,目标是能通过一个域名访问到本地的一个服务
**使用docker部署企业微信机器人**
(代码在文章开头已经提供了,具体如下)
> docker run -d -p 3201:3200 \--name openai-wework \-e api_key="[chatgpt的APIkey]" \-e app_port=":3200" \-e app_model="text-davinci-003" \-e wework_token="[企业微信自建应用的API token]" \-e wework_encodingAeskey="[企业微信自建应用的encodingAeskey]" \-e wework_corpid="[企业微信企业唯一ID]" \-e wework_secret="[企业微信自建应用的secret]" \-e wework_agentid="[企业微信自建应用的agentid]" \ibfpig/openai-wework:1.0.0
3. 查看日志,确定服务运行是否正常
> docker logs -f openai-wework
4. 去企业微信测试即可
## 关于请求OpenAI的参数
这里会简单做个说明,后边在详细聊如何训练OpenAI的时候会做更详细的说明
> prompt: "需要给OpenAI理解文字",frequency_penalty: 0, #一个介于-2.0和2.0之间的数字。当它是正数时,会对新的token进行惩罚,根据它们在文本中已经出现的频率,减少模型重复相同文本的可能性。这个参数可以控制模型生成文本的创新性和多样性。model: "text-davinci-003", # 模型ID,目前API里效果最好的就是text-davinci-003,但是也是最慢的temperature: 0.7, # 0~1之间,随机性,越高,随机性越高presence_penalty: 0, # -2.0~2.0之间,是一个用于控制模型输出是否跟之前已经输出的文本相关的参数。如果这个参数的值为正数,那么模型会更倾向于生成与之前不同的单词,从而使生成的文本更加丰富多样,涉及到更多的话题。max_tokens: 2000, # 生成文本时所允许的最大单词数量top_p: 1 # 这种方法会限制生成的文本只包含最可能的一些词,而不会像用温度进行抽样一样随机生成词语。同时,通常建议只更改temperature或top_p中的一个参数,而不是同时更改两个参数。
## node、PHP、Python、golang请求OpenAI的代码示例
1. javascript(使用axios)
> axios({"method": "POST","url": "https://api.openai.com/v1/completions","headers": {"Authorization": "Bearer [你自己的API key]","Content-Type": "application/json; charset=utf-8"},"data": {"prompt": "你好","frequency_penalty": 0,"model": "text-davinci-003","temperature": 0.7,"presence_penalty": 0,"max_tokens": 2000,"top_p": 1}})
2. php
> // Include Guzzle. If using Composer:// require 'vendor/autoload.php';use GuzzleHttp\Pool;use GuzzleHttp\Client;use GuzzleHttp\Psr7\Request;$client = new Client();$request = new Request("POST","https://api.openai.com/v1/completions",["Authorization" => "Bearer [你自己的API key]","Content-Type" => "application/json; charset=utf-8"],"{\"model\":\"text-davinci-003\",\"prompt\":\"\\u4f60\\u597d\",\"max_tokens\":2000,\"temperature\":0.7,\"top_p\":1,\"frequency_penalty\":0,\"presence_penalty\":0}");$response = $client->send($request);echo "Response HTTP : " . $response->getStatusCode() . "";
3. python
> # Install the Python Requests library:# `pip install requests`import requestsimport jsondef send_request():# 对话# POST https://api.openai.com/v1/completionstry:response = requests.post(url="https://api.openai.com/v1/completions",headers={"Authorization": "Bearer [你自己的API key]","Content-Type": "application/json; charset=utf-8"},data=json.dumps({"prompt": "你好","frequency_penalty": 0,"model": "text-davinci-003","temperature": 0.7,"presence_penalty": 0,"max_tokens": 2000,"top_p": 1}))print('Response HTTP Status Code: {status_code}'.format(status_code=response.status_code))print('Response HTTP Response Body: {content}'.format(content=response.content))except requests.exceptions.RequestException:print('HTTP Request failed')
4. golang
> package mainimport ("fmt""io""net/http""bytes")func send() {// 对话 (POST https://api.openai.com/v1/completions)json := []byte(`{"prompt": "你好","frequency_penalty": 0,"model": "text-davinci-003","temperature": 0.7,"presence_penalty": 0,"max_tokens": 2000,"top_p": 1}`)body := bytes.NewBuffer(json)// Create clientclient := &http.Client{}// Create requestreq, err := http.NewRequest("POST", "https://api.openai.com/v1/completions", body)// Headersreq.Header.Add("Authorization", "Bearer [你自己的API key]")req.Header.Add("Content-Type", "application/json; charset=utf-8")// Fetch Requestresp, err := client.Do(req)if err != nil {fmt.Println("Failure : ", err)}// Read Response BodyrespBody, _ := io.ReadAll(resp.Body)// Display Resultsfmt.Println("response Status : ", resp.Status)fmt.Println("response Headers : ", resp.Header)fmt.Println("response Body : ", string(respBody))}

🚀 快速部署OpenAI机器人,轻松实现智能对话!
想在企业微信、飞书或钉钉上快速部署一个ChatGPT机器人吗?只需一行Docker命令,即可实现自然语言理解和生成功能!本文详细介绍了如何通过OpenAI API与企业微信结合,打造专属智能助手。
💡 亮点:
🔗 GitHub项目地址: https://github.com/thlz998/openai-bot
📌 一句话总结: 用Docker一键部署,让ChatGPT成为你的企业微信智能助手!
#OpenAI #ChatGPT #企业微信 #智能机器人 #Docker #编程教程