问题 1: 什么是RPA,它在抓取头条文章图片中的作用是什么?
回答: RPA(机器人流程自动化)是一种自动化技术,用于模拟人类操作计算机的行为。在抓取头条文章图片中,RPA可以通过获取网页元素的属性值(如图片的src属性)来自动下载图片。
问题 2: 如何获取网页中图片的链接?
回答: 图片的链接通常保存在网页元素的src属性中。通过RPA的“获取元素属性”指令,可以提取src属性的值,从而获取图片的链接。
问题 3: 在RPA中,如何测试是否成功获取了图片的链接?
回答: 可以使用RPA的“打印指令”来输出获取到的src属性值,从而测试是否成功获取了图片的链接。
问题 4: 如何通过RPA下载获取到的图片?
回答: 使用RPA的“下载文件”指令,并将之前获取到的图片链接作为下载地址,即可下载图片。
问题 5: 在抓取图片时,是否所有图片的链接都保存在src属性中?
回答: 通常情况下,图片的链接保存在src属性中,但也有例外情况。在特殊情况下,需要根据具体网页结构进行特殊处理。
问题 6: 文章中提到的方法是否适用于所有网页?
回答: 文章中提到的方法主要适用于通过src属性保存图片链接的网页。对于其他类型的网页,可能需要调整或采用不同的方法。
问题 7: 使用RPA抓取图片的完整流程是什么?
回答: 完整流程包括:1. 获取已打开的网页对象;2. 获取图片元素的src属性值;3. 使用获取到的链接下载图片。
问题 8: 文章中提到的实操步骤是否包含截图示例?
回答: 是的,文章中包含了多个截图示例,展示了每一步的具体操作和结果。
问题 9: 如果遇到图片链接不在src属性中的情况,该如何处理?
回答: 需要根据网页的具体结构进行分析,找到图片链接的存储位置,并调整RPA的指令以获取正确的属性值。
问题 10: 文章提到的RPA方法与其他抓取方法(如JS下载)相比有什么优势?
回答: RPA方法简单直观,适合自动化流程,尤其适合不需要编写复杂代码的场景。而JS下载可能需要更多的编程知识,适合需要高度定制化的需求。
 1. 获取元素信息
1. 获取元素信息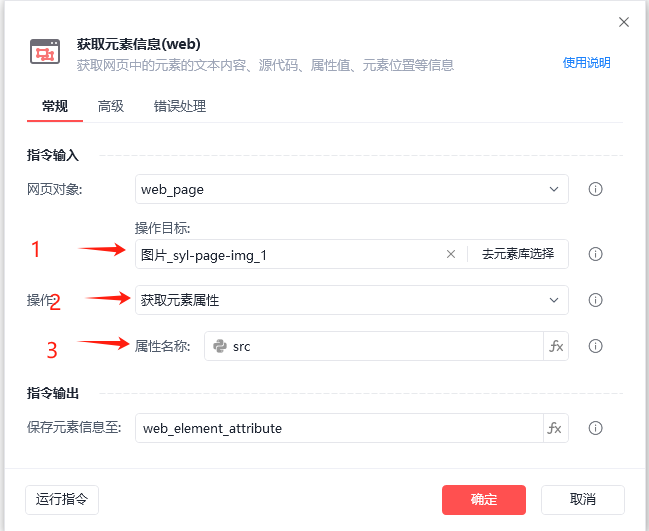 说明:
说明: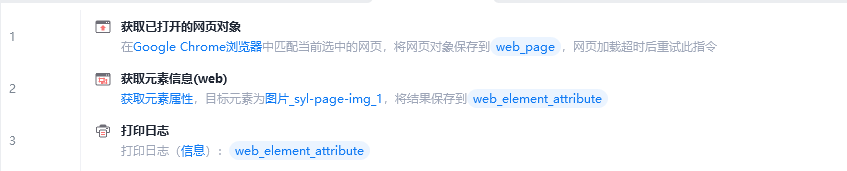
 1. 下载图片
1. 下载图片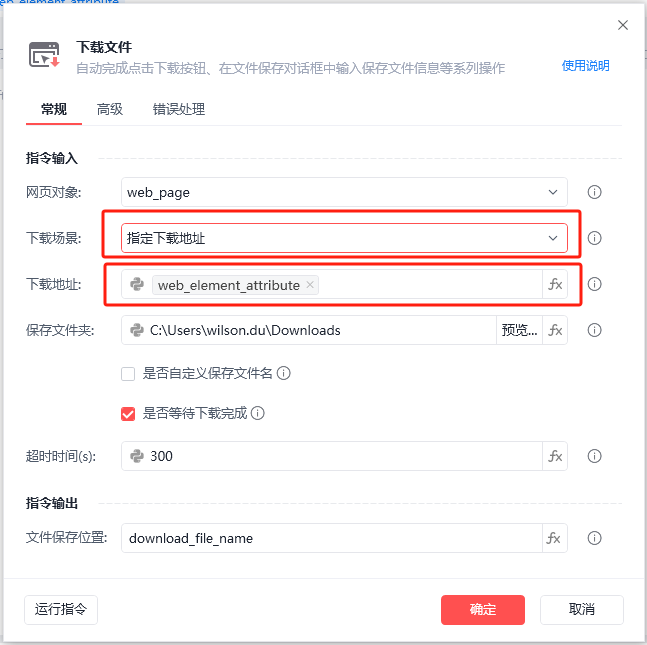 说明:
说明: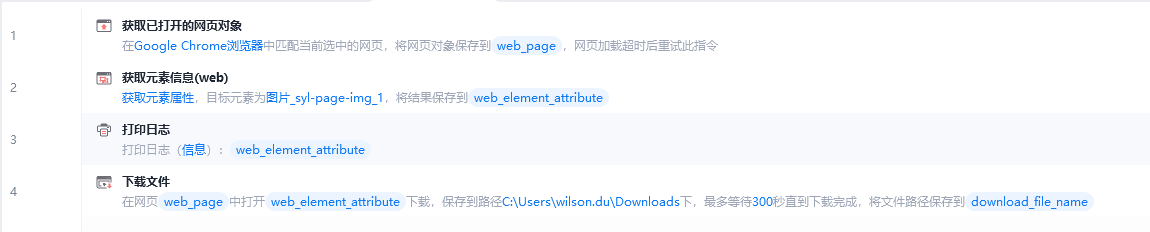


🚀 轻松抓取头条文章图片! 🖼️
想要快速获取网页上的图片?试试RPA指令吧!只需简单几步,你就能轻松下载头条文章中的图片。📲
步骤超简单: 1️⃣ 获取网页对象
2️⃣ 捕获图片并获取src属性
3️⃣ 下载图片到本地
无论你是技术小白还是RPA高手,这个方法都能帮你高效完成任务!💡
👉 点击这里了解更多详细教程!
#RPA #网页抓取 #技术教程 #效率提升