本没有战争,但是有了软件,就有了分工,就有了争议,或者说成为琢磨的对象。指标与标签也是如此。
指标的定义与分类
指标是数据分析师每天都在打交道的对象。比如零售企业里,销售额的非常常见的一个指标。指标在海外的企业级数据软件产品一般对应为Metric,翻译过来是度量的意思,个人理解“度量”是“度量衡”(度——计量长短用的器具称为度;量——测定计算容积的器皿称为量;衡——测量物体轻重的工具称为衡)的一种简化表达。因为长度、体积可能是最常用的一些描述性指标。 而指标一般也用于量化描述一个场景的好与坏,长或者短等。
度量衡都会带上单位,比如长度的公里、米等;那么指标是否一定需要带单位呢? 大部分指标都会带上,但是一些占比类,百分比,或者比值类的指标就不需要单位了。
“销售额”是一个指标,那么“昨日的销售额”跟“本月的销售额”是不是也是指标呢?这几者的区别又是什么? 我们先从商业与工程角度出发,来尝试对指标进行一个类别的划分。
从计算逻辑层面对指标进行分类
这里引用阿里巴巴数据中台方法论提出的指标分类方法。
- 原子指标:一般表征一个业务动作最原始的“幅度”大小, 比如支付金额、销售订单数;这些指标一般都无法继续做拆解。
- 衍生指标:在原子指标的基础上,叠加 ①统计周期 ② 业务限定(过滤条件)③ 统计粒度 这些约束条件;一个原子指标可以衍生出非常多,甚至成百上千个指标。
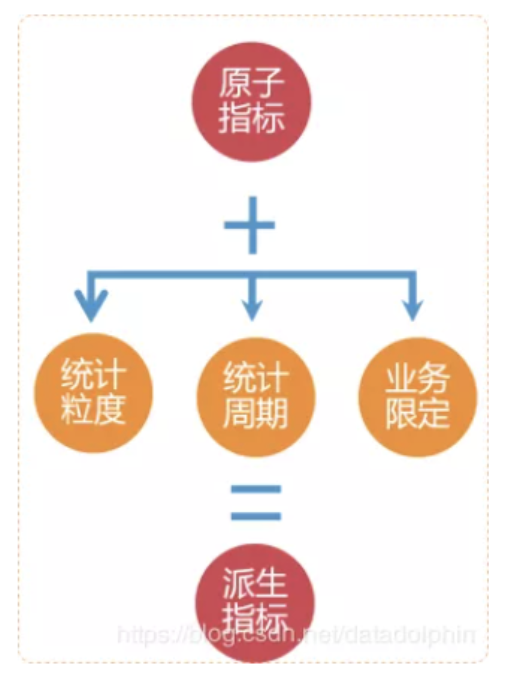 图:阿里巴巴数据中台指标定义方式
图:阿里巴巴数据中台指标定义方式
衍生指标结合统计日期(或者时间)这个概念就是一个明确的描述值。举个例子,在T+1 的计算模式(也就是隔日计算)下, 2021年12月10日计算的「最近7天线下渠道生鲜品类的销售额」就是指 2021年12月3日到2021年12月9日线下渠道生鲜品类的总销售额。

从计算与展现层面对指标进行分类
- 报表级别的指标:即数据分析师只是引入一个指标的计算规则,比如就是销售额的累计,但是具体算哪几天,算哪些渠道,算哪些品类是根据报表这一个级别的配置、甚至是即席的查询条件来决定的。 在第一张报表里,可能展现的是某一天某个渠道的销售额;在第二张报表中,展现的是某一天某个品类的销售额。
- 指定计算粒度的指标:相比报表级别的指标,指定了计算粒度的指标的计算规则是相对固定的,比如 渠道累计销售额,是指在渠道这个维度上聚合后的销售额。
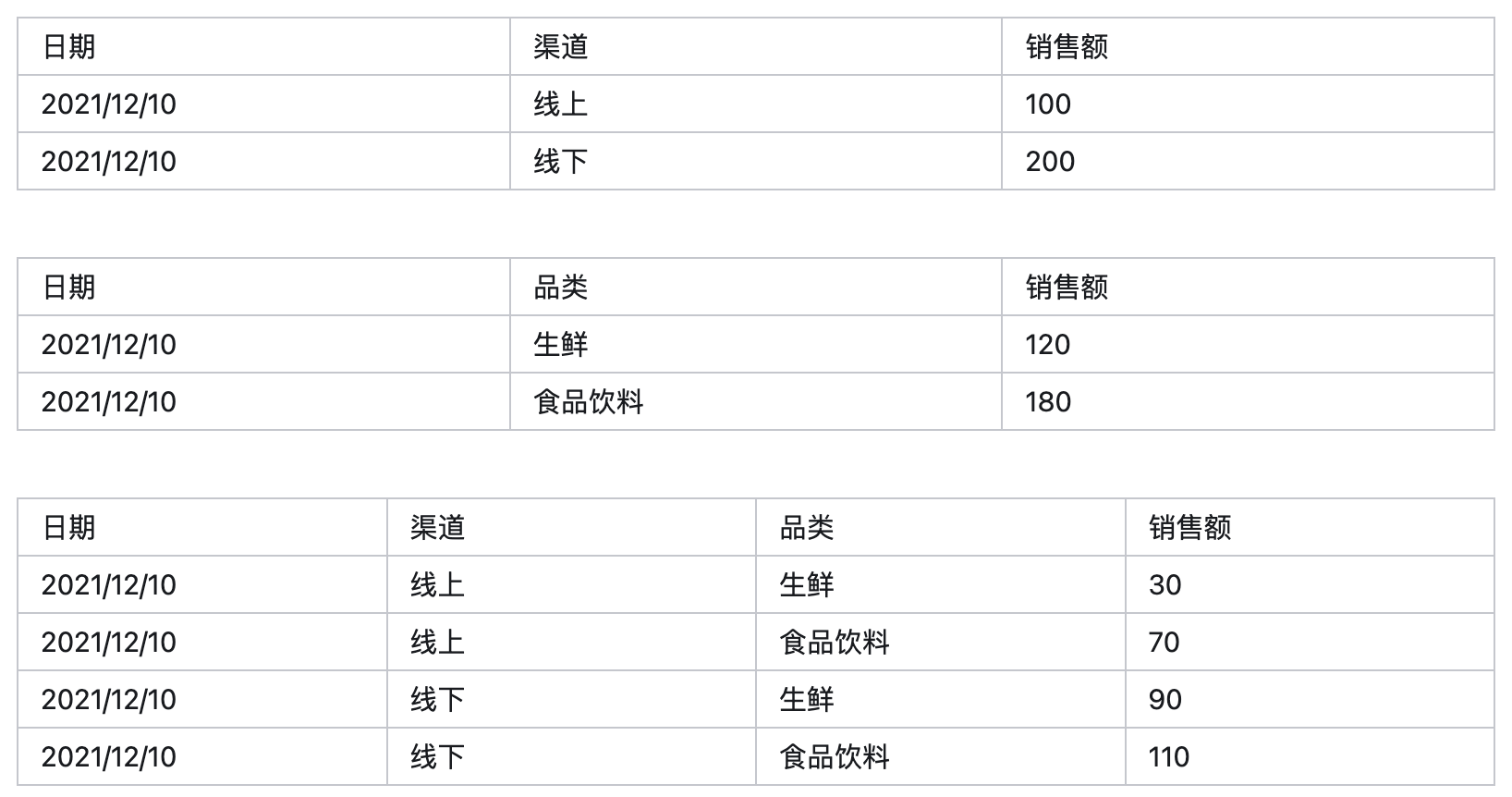
报表级别的指标示例:上述三张表的分析粒度分别是 ① 日期 x 渠道 ② 日期 x 品类 ③ 日期 x 渠道 x 品类
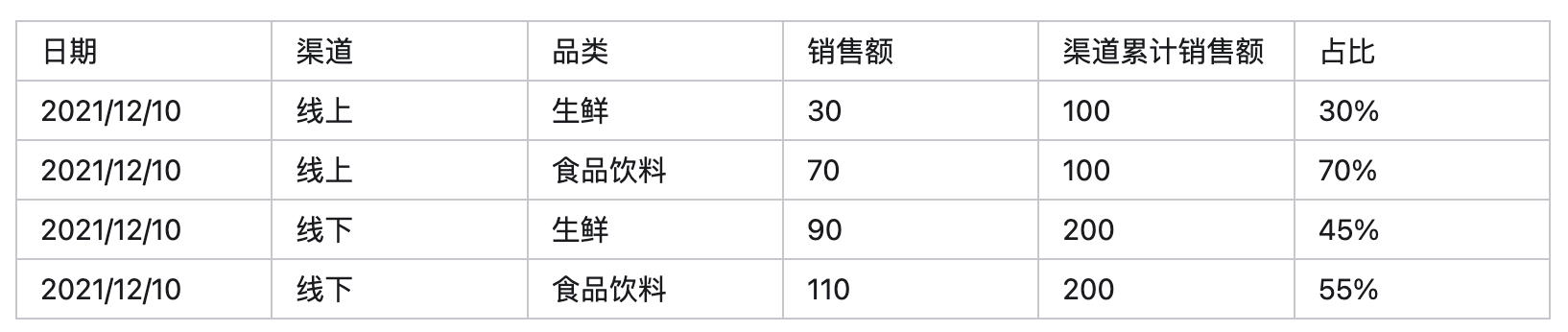 图表:报表级别的指标与指定计算粒度的指标混合显示示例
图表:报表级别的指标与指定计算粒度的指标混合显示示例
从商业运营层面对指标进行分类
以电商行业为例,营业销售额(GMV)可以被拆解成为用户浏览量×转化率×客单价。 这里销售额是一个结果性的指标,而用户浏览量、转化率、客单价都是过程性的指标,可以用于日常运营策略的设计。
- 结果性指标:一般用于整体运营效果的考核
- 过程性指标:一般用于具体运营策略的设计
公司考核团队,一般都拿结果性指标来考核,具体怎么实现这个指标,设计怎样的策略,那就是具体一线团队要做的事情。 当然,到了一线团队实际运营动作时,每一个过程性的指标也会被定义为一个KPI(Key Performance Index)来做进一步的拆解。比如客单价就可以分为老客的客单价与新客的客单价,因为提升老客的客单价与新客的客单价的思路是可以做差异化的。
标签的来源与分类
随着消费互联网的蓬勃发展,精准营销、数据驱动运营等方法论的流行,这些方法论背后所依赖的标签也进入数据分析师日常讨论与关注话题之中。
标签一般是基于特定的业务运营,比如广告投放或者用户运营目标,来对目标对象(最初以消费者为主)的一种描述,简单的比如男女,复杂的比如高价值用户,中价值用户等。2019年9月,阿里巴巴天猫与贝恩咨询公司发布《2019年中国快消品线上策略人群报告》就引入了八大策略人群这样的概念,其实也是对天猫的消费者打上了一个标签。
在此次策略人群的划分过程中,基于贝恩多年的洞察积累,结合各个细分行业广泛使用的人群属性标签(如小仙女、都市潮男等),在天猫淘宝大快消海量消费者数据的加持下,我们对多个反映消费行为偏好的核心指标聚类分析,数次迭代,最终总结出八大特征鲜明的策略人群。他们是:新锐白领、资深中产、精致妈妈、小镇青年、Gen Z(Z世代)、都市银发、小镇中老年和都市蓝领。他们约占大快消平台用户数的八成,贡献九成以上的销售额。
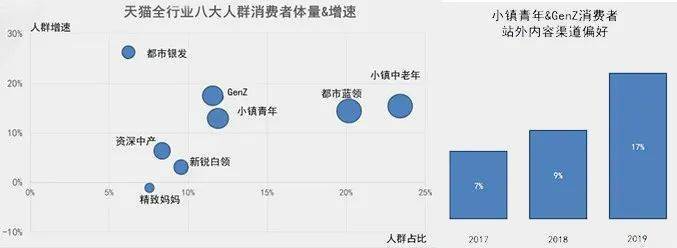 图:天猫全行业八大人群消费者体量&增速
图:天猫全行业八大人群消费者体量&增速
标签在业务层面分类
每个品牌、平台其实都有自己的分类方式以满足不同时期不同的商业诉求,以下给出腾讯广告的一种分类方式。
 图 腾讯广告的标签分类(一级分类)
图 腾讯广告的标签分类(一级分类)
标签的工程学分类
- 数值类标签:一般都可以对应到指标,比如最近30天的登录天数
- 非数值类标签:一般都对应到用户的属性,比如性别、居住的城市等;如果本没有这个属性,那么其实加工出来的标签就可以是用户属性。 比如上文提到天猫给消费者打上了八大人群标签,比如Z世代,小镇青年等。
标签的来源
- 直接从用户属性中提取 ,比如性别、年龄(每年在变化)、星座(一般不变化,除非用户修改生日信息)等
- 算法预测,比如虽然用户填写的是男性,但是行为特征可能接近女性,那么在预测性别中,这个用户可能就会打上女性的标签(或者是一个男性用户注册的账号,但是实际使用人是女性)
- 对行为属性进行简单加工,比如最近7天或者30天的登录次数(表征活跃情况)
- 对行为或者用户属性进行复杂加工,比如上面提到的八大人群标签,即包含了年龄属性又包含居住属性
标签与指标的相同与不同
那么标签与指标有哪些相同的点,哪些不同的点呢?
-
数据类型
-
指标:基本都是数值型的,包含整数与小数
-
标签:以文本型为主,也有数值型的
-
维度与维度属性:以文本型为主
-
应用目的
-
标签:用于圈选人群,描述人群
-
指标:用于描述人群,分析人群;有时候也用于圈选人群,比如把一个地方里年收入大于12万的人圈选出来
-
分析层面上的技术处理方式(聚合方式)
-
标签:一般对应计数(比如统计男性的比例)、无处理(直接显示)
-
指标:一般包含累加、求最大值、求最小值、求均值等处理方式
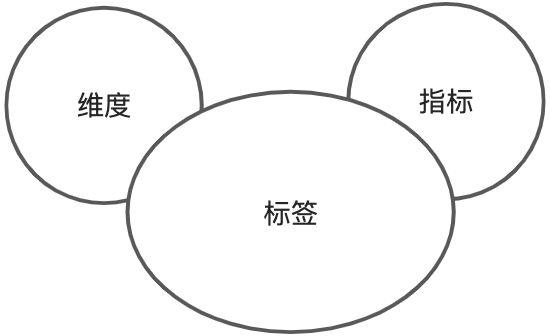 图:维度、标签、指标三者关系说明
图:维度、标签、指标三者关系说明
几者的重叠:
- 部分指标就是标签,比如年度销售金额;部分指标会做分段处理后形成一个标签,比如 年龄。纯粹的一个年龄数字分析意义并不大,一般都会结合实际的业务运营场景进行分段处理。比如把成年与未成年的分开,具体的,我们在《数值标签的分段化处理》小节中再展开讨论。
- 大部分维度与属性都可以是标签。 比如性别,居住城市等。
不重叠部分:
标签里还有一部分既不属于维度,也不属于指标? 比如多值型的标签,以及KV(Key - Value)型的。比如一个人对于多个咖啡茶饮品牌的偏好,比如对星巴克、奈雪、喜茶都有偏好,但是偏好度不同,分别是0.8、0.6、0.3。 这类标签可以被很多消费者运营产品所使用,但是这类标签如果要被用于做分析,就需要进行数据的二次加工。
其实还有个词,特征(Feature)也跟指标、标签这些概念有这密切联系。这个概念主要是算法科学、数据挖掘岗位使用。 一个标签可以是一个特征,比如性别男女。
标签的内部战争
标签和指标有“战争”(争论),其实标签内部也有。 比如, 男与女,这是一个标签么?可以是。那么性别是一个标签么? 也可以是。那这两种的区别在哪里? 其实是标签与标签值的争论,在表述上都没有问题,在数据使用层面去做个划分即可。 那么遵循什么标准呢?业界有什么共识呢? 有一个思路供参考,你希望用户先看到哪个字眼,就把他当做标签?
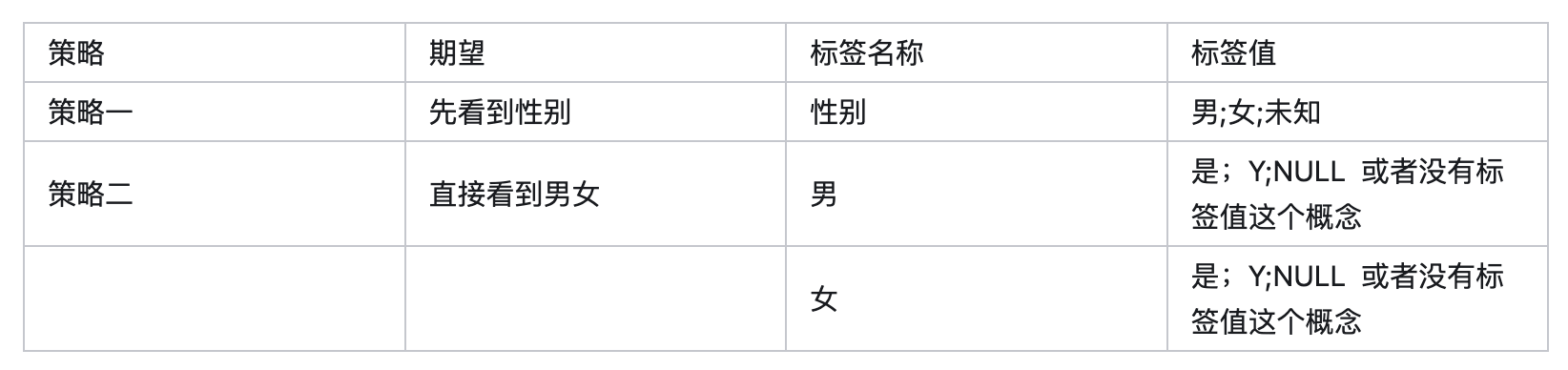
这里Y表示YES的意思,在技术处理上也有多种形式。市面上采用策略一的比较多,尤其是用关系型数据表来存储标签的时候;策略二一般与非关系型数据库这个技术方案一起出现,比如MongoDB。
当然,部分标签的管理工具或者说明文档中,也会把男、女做为四级标签。但是用户在使用的时候,需要先点开上一级标签,就是性别,然后在里面选择。
上文拿了性别作为标签的一个例子,具体的标签值在不同国家、不同产品有不同的处理方式,比如脸书公司在用户界面上就给出了56 种选项允许用户选择。还是挺好奇脸书广告平台上会开放多少种性别选项让广告主进行选择。
在国内,如果遵循《中华人民共和国国家标准:人的性别代码(GB 2261-1980)》,那么就是四大类:0 - 未知的性别;1 - 男性;2 - 女性;9 - 未说明的性别。 此外,部分标签的管理以及标签值的定义,还会跟公司的主数据系统进行关联。 比如男性或者女性,到底是存1跟2,还是F跟M,还是就直接存储中文,本文就不详细展开了。
参考资料
- 度量衡:《现代汉语·辞海》光明日报出版社
- 数仓中的一些概念 https://blog.csdn.net/penriver/article/details/118890984
- 天猫大快消8大策略人群 https://www.sohu.com/a/343932556_282725
- 国内数据类产品消费者标签体系汇总 https://www.yuque.com/jiezhao/ontheway/lqul9l
- 脸书的56个性别选项 https://www.guokr.com/article/438003/


📊 指标 vs 标签:数据分析的核心概念解析
你是否曾好奇,数据分析中的“指标”和“标签”到底有什么区别?🤔
🔍 指标:用于量化描述业务场景,比如销售额、转化率等,通常以数值形式呈现,帮助衡量业务表现。
🏷️ 标签:用于描述人群或对象,比如性别、用户类型等,常用于精准营销和用户分群。
💡 关键区别:
📈 应用场景:
无论你是数据分析师、运营人员,还是对数据驱动决策感兴趣,了解指标与标签的异同,都能帮助你更好地利用数据提升业务效率!🚀
#数据分析 #指标与标签 #数据驱动 #精准营销 #运营策略