需求:给出参考人物,脸部不变,姿势不变,其他全部变,如下图,左侧为参考图,右侧为全自动出图

实现思路:
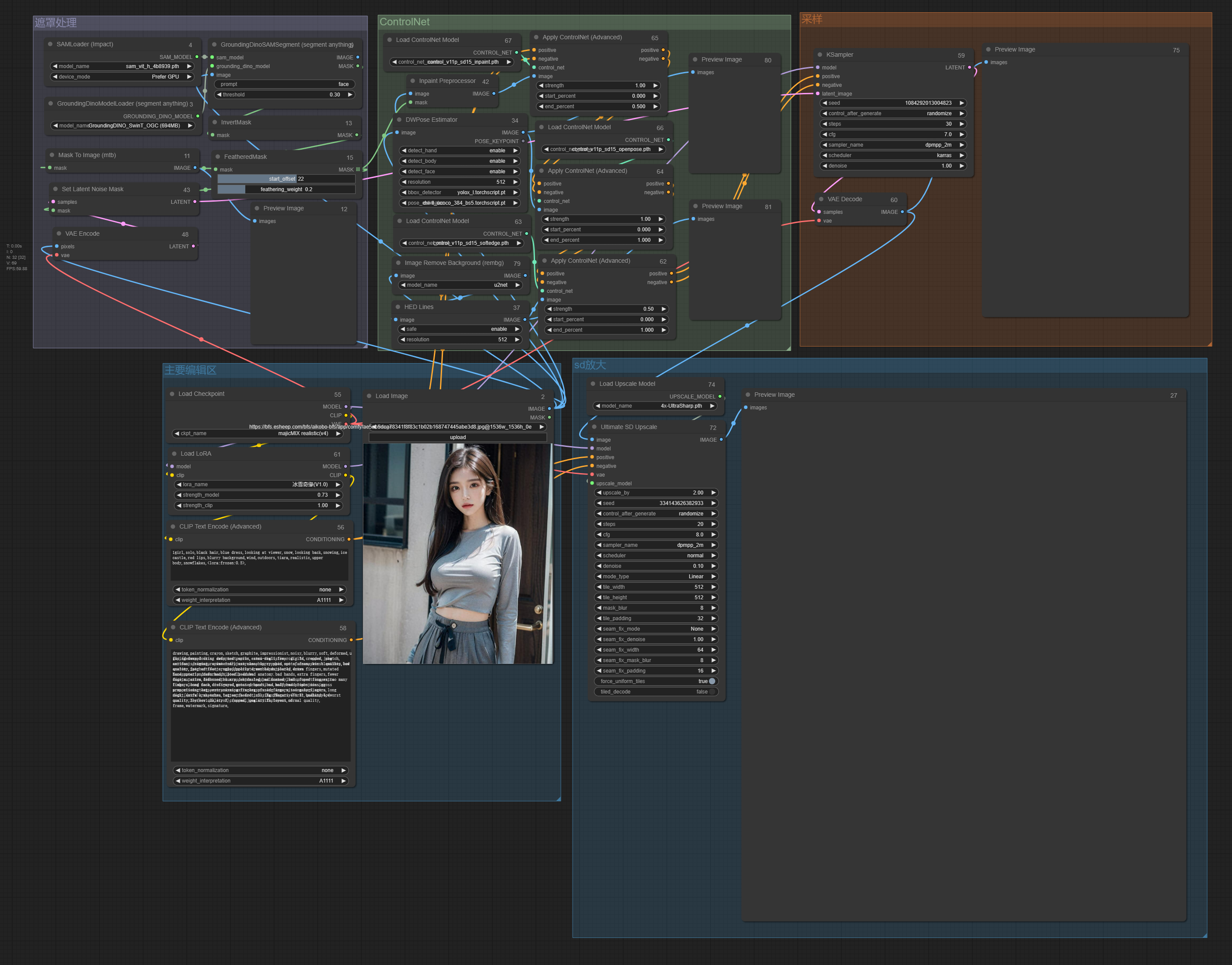
1、需求为脸部不变:需要把脸部遮住,出图时不被重绘
2、需求为姿势不变:需要用ControlNet控制姿势
3、其他全变:正常图生图即可
分步实现:
1、制作蒙版遮住脸部
制作蒙版是把脸部蒙版精准抠出,我们需要通过分割算法把脸部自动抠出,这里用到可以分割一切的seg(segment anything)
节点官网:https://github.com/storyicon/comfyui_segment_anything
根据官网示例可以看到,通过这个sam模型可以很方便的制作出一个脸部模型:
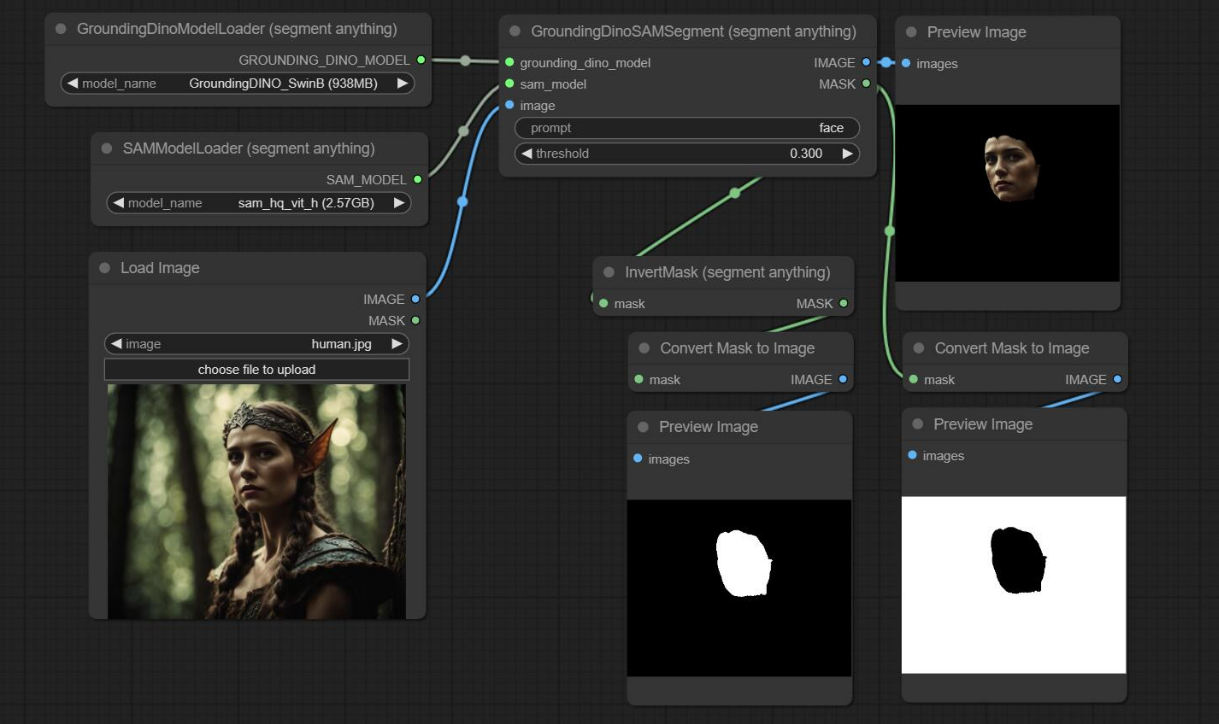
比葫芦画瓢,于是,小姐姐的脸完美扣出来了:
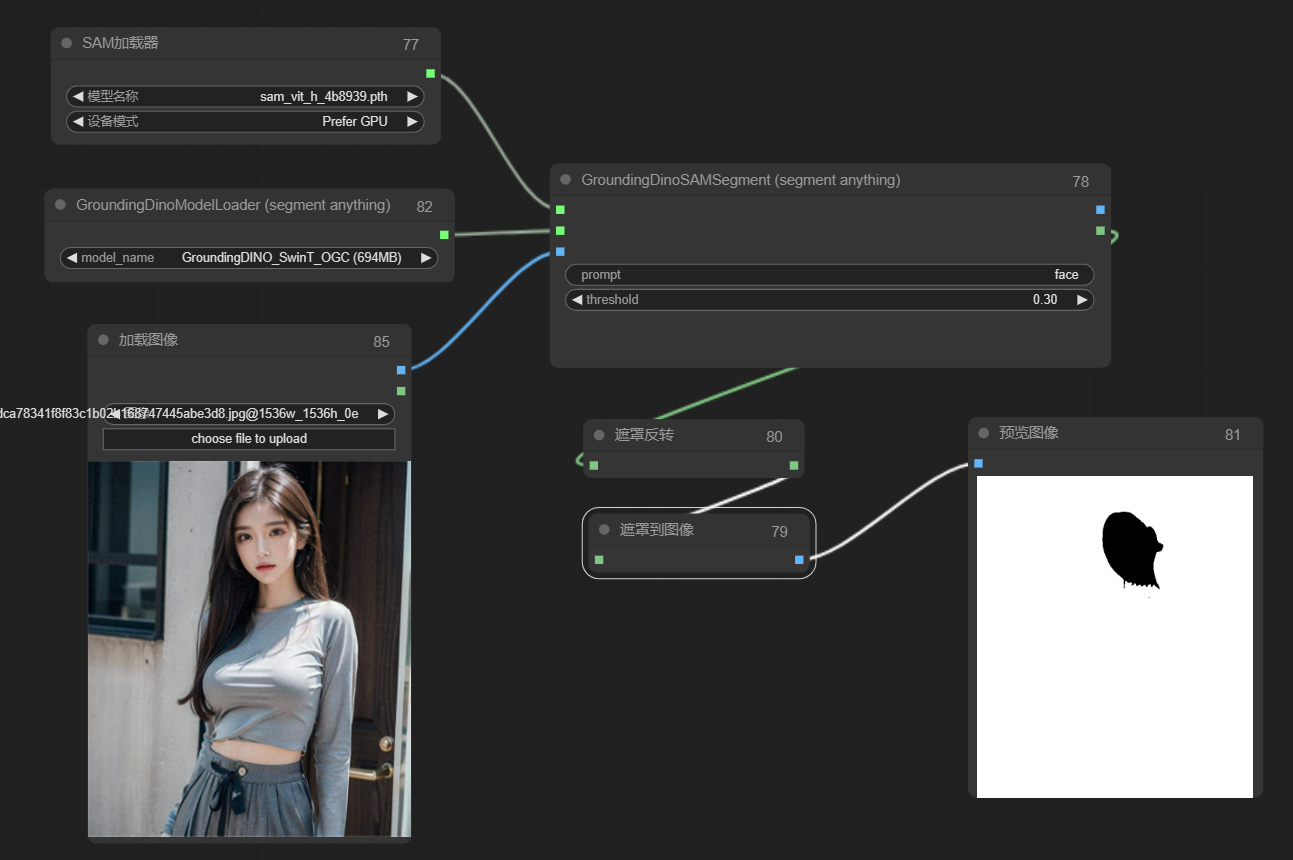
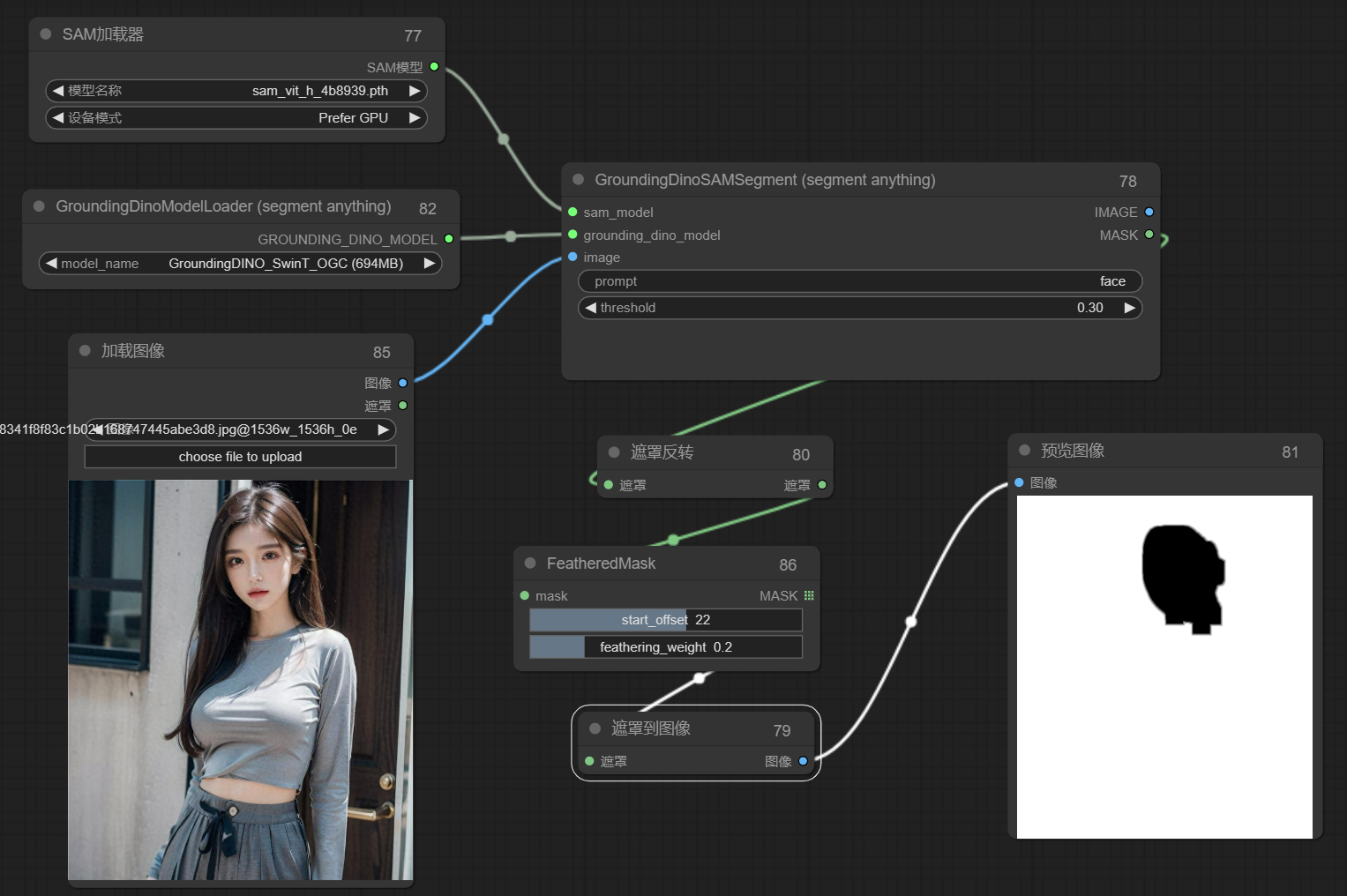
边缘羽化处理,这里通过FeatheredMask节点
节点网址:https://github.com/shadowcz007/comfyui-mixlab-nodes
通过FeatheredMask节点完美实现对边缘的羽化处理,如下图可以看到边缘明显不那么锐利:
2、图生图并加入lora控制写真风格
加载对应的大模型和lora,这里主要注意lora要和大模型相互匹配,通过lora模型的说明上可以看到使用什么大模型,如下图,冰雪奇缘这里用的麦橘V7
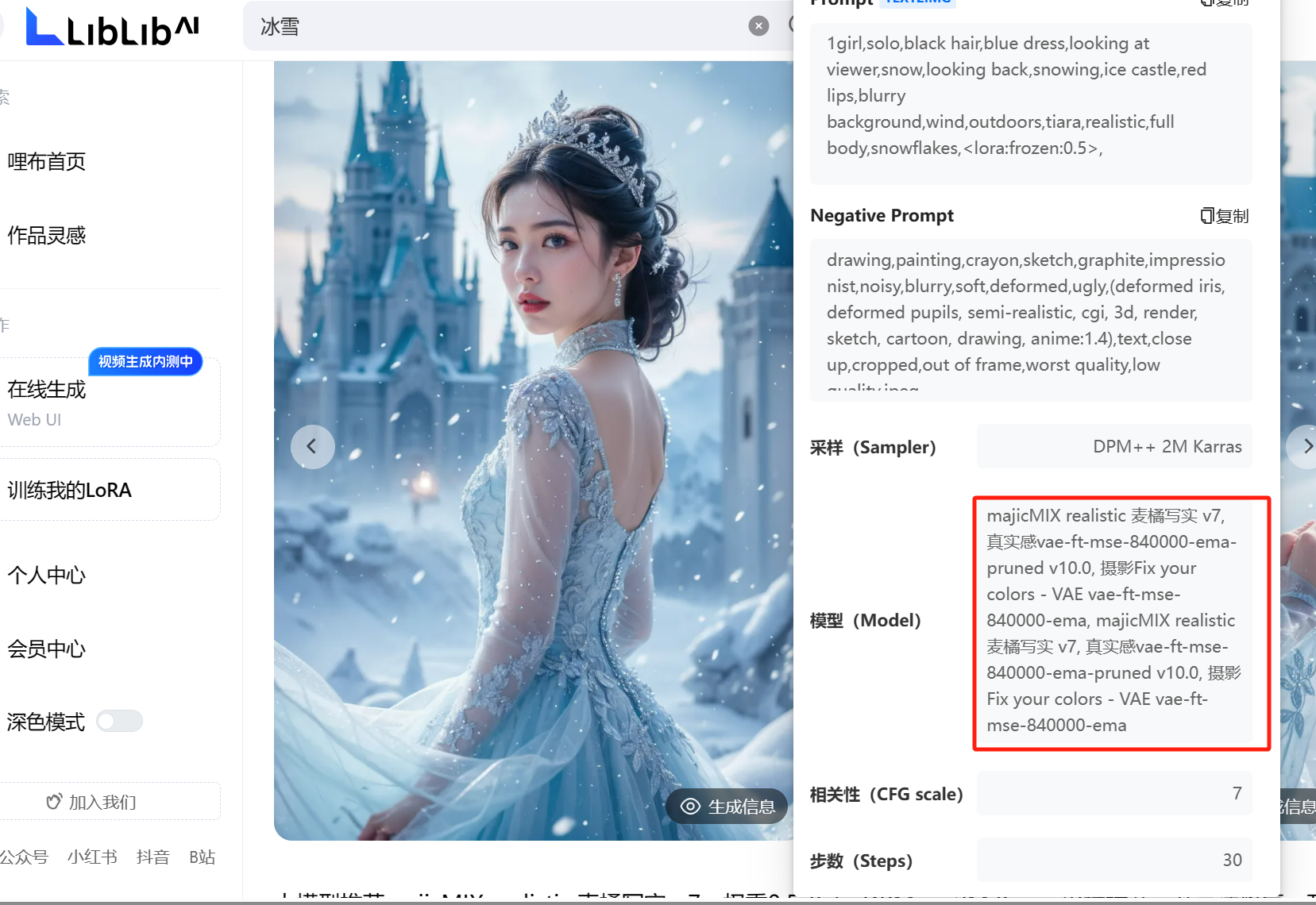
这里属于基础部分,我就直接放流程图了,参数调节根据lora模型要求填写即可
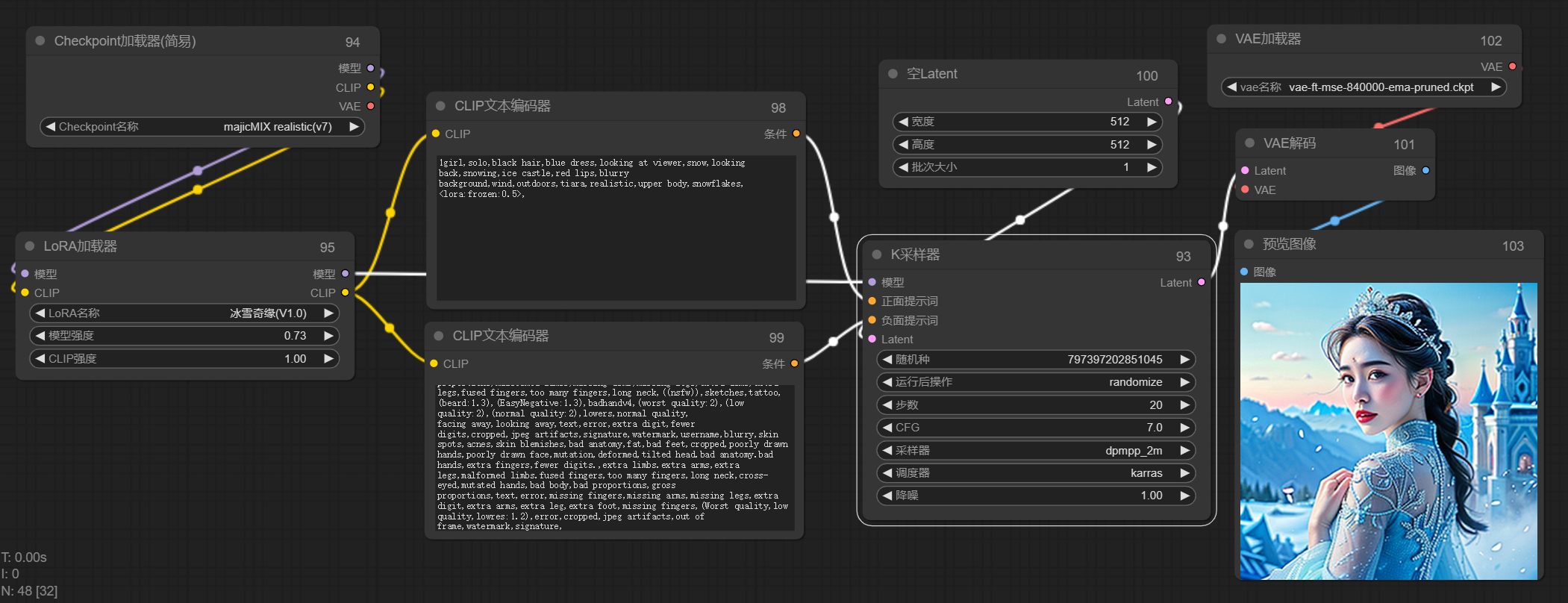
但是!这里依然有有一些细节需要注意,如果我们选择的适用于webui的提示词和参数配置的lora模型,我们需要用**webui的提示词权重插值的方法,**否则出的图和lora模型的表现有一定的差距。
啥意思呢,讲人话,就是目前大部分lora模型给出的效果图以及提示词都是从webui上得出得结论,但并不一定适用于comfyui,两种方式对提示词编码时的权重插值是有差异的,这也是经常有小伙伴通过ComfyUI还原WebUI时经常发现不能完美还原的一个非常非常重要的原因。
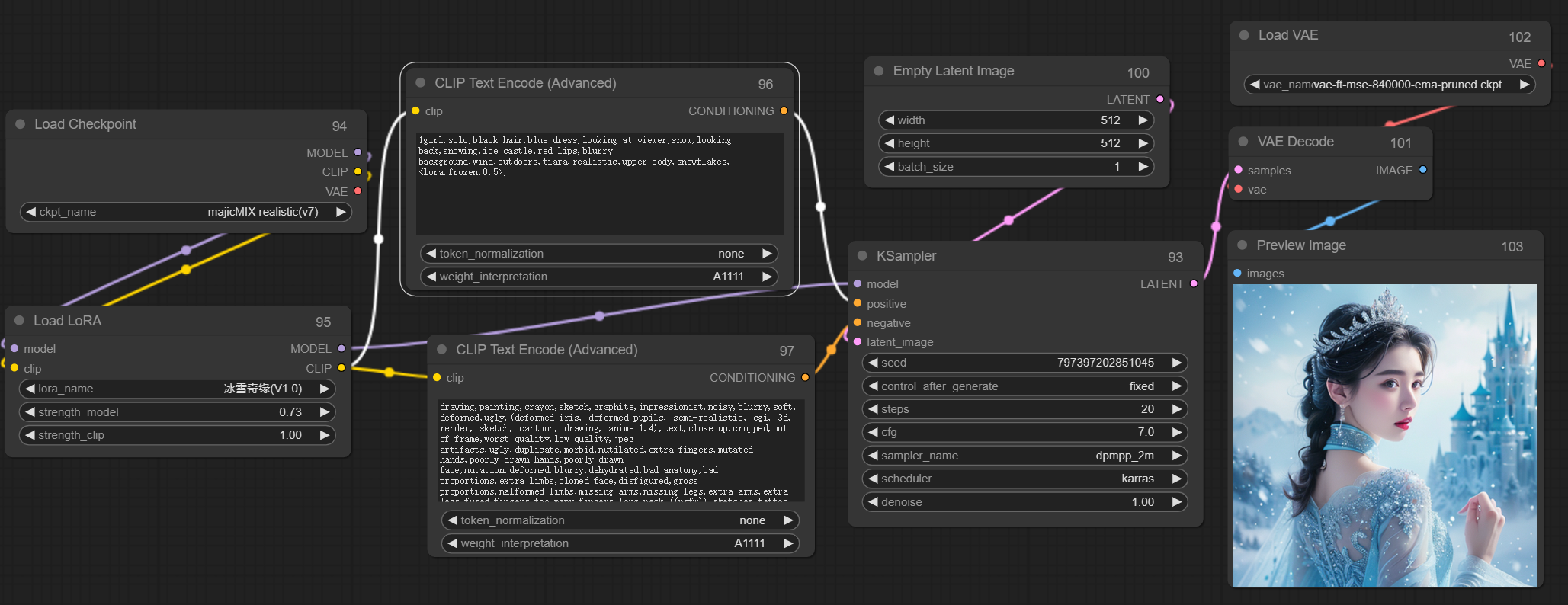
因此为了保证完美还原,这里又引入了一个节点:
节点网址:https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb
这个节点允许我们把权重插值方法改为A1111,也就是WebUI的提词权重插值方式,如下图:

根据上面接上,我们把之前的流程再重新修改,于是如下图:
可以看出两张图是有明显差别的,第一次的图明显锐化比较严重,第二次就好很多了。
到这里,SD基础设置中的前半部分就ok了,后边就是对蒙版内容和现在的采样器进行结合
这里可以加入一点噪声,让重绘幅度大一些
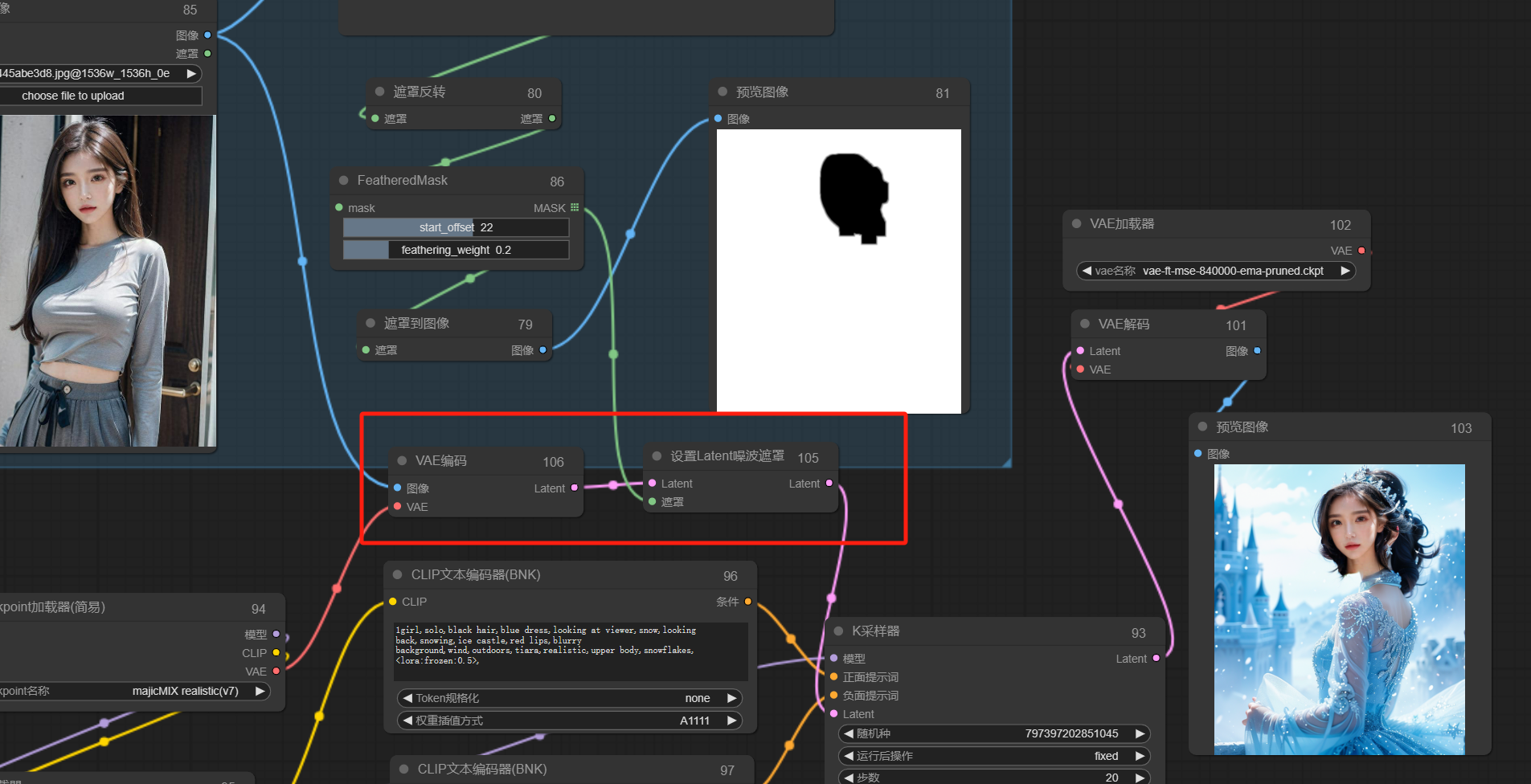
如上图,我们生成测试一下,发现遮罩部分完美把脸部迁移了,背景也重绘了,目前达到我们的效果。
剩下的就交给ControlNet来处理吧。
3、ControlNet控制姿态
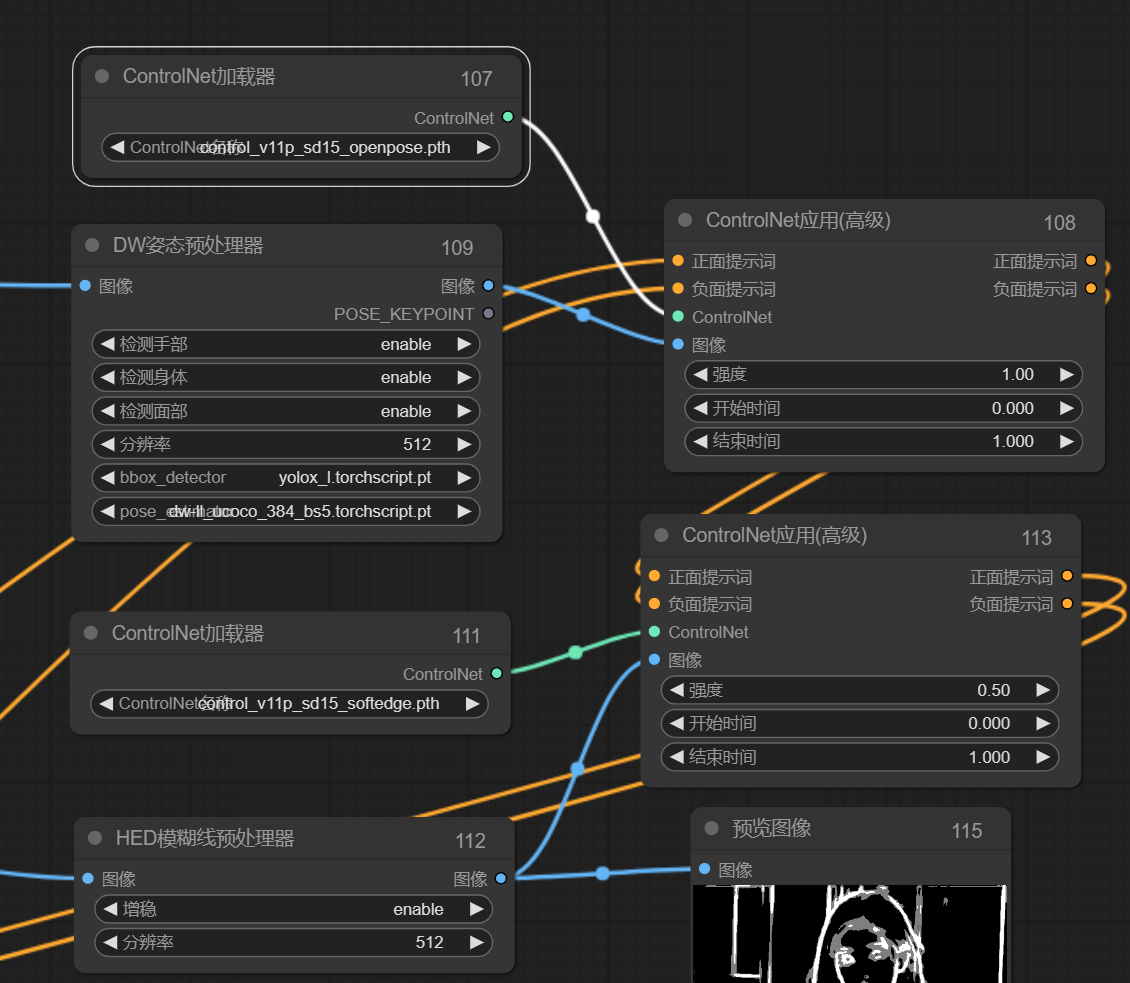
这里主要用了openpose和lineart来控制人物的姿态和脸型,确保生成的图正好被遮罩覆盖
用到了comfyui_controlnet_aux,和ComfyUl-Advanced-ControlNet
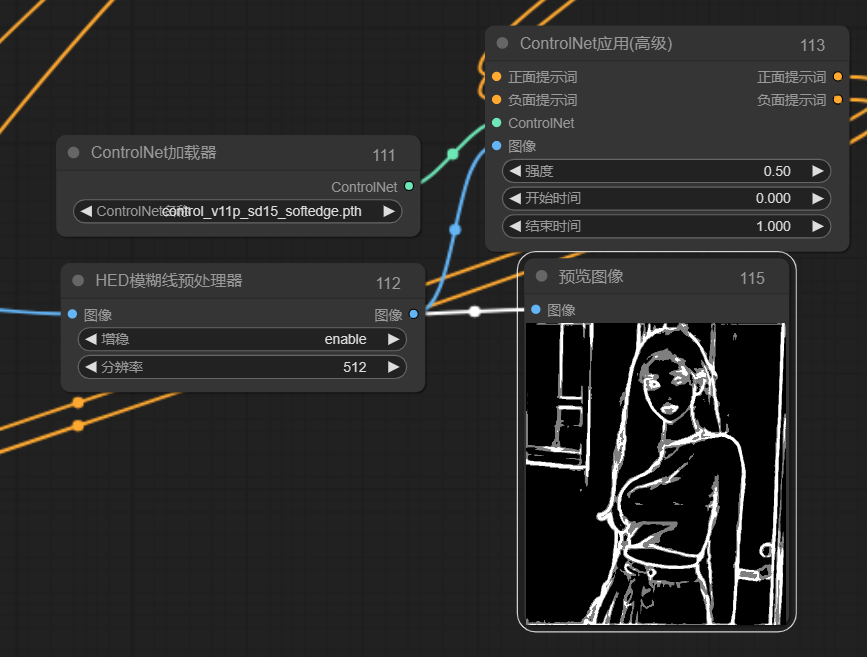
这里发现背景中的线条也被识别了,对我们重绘背景不利,因此需要先把背景去除,再进行线条约束
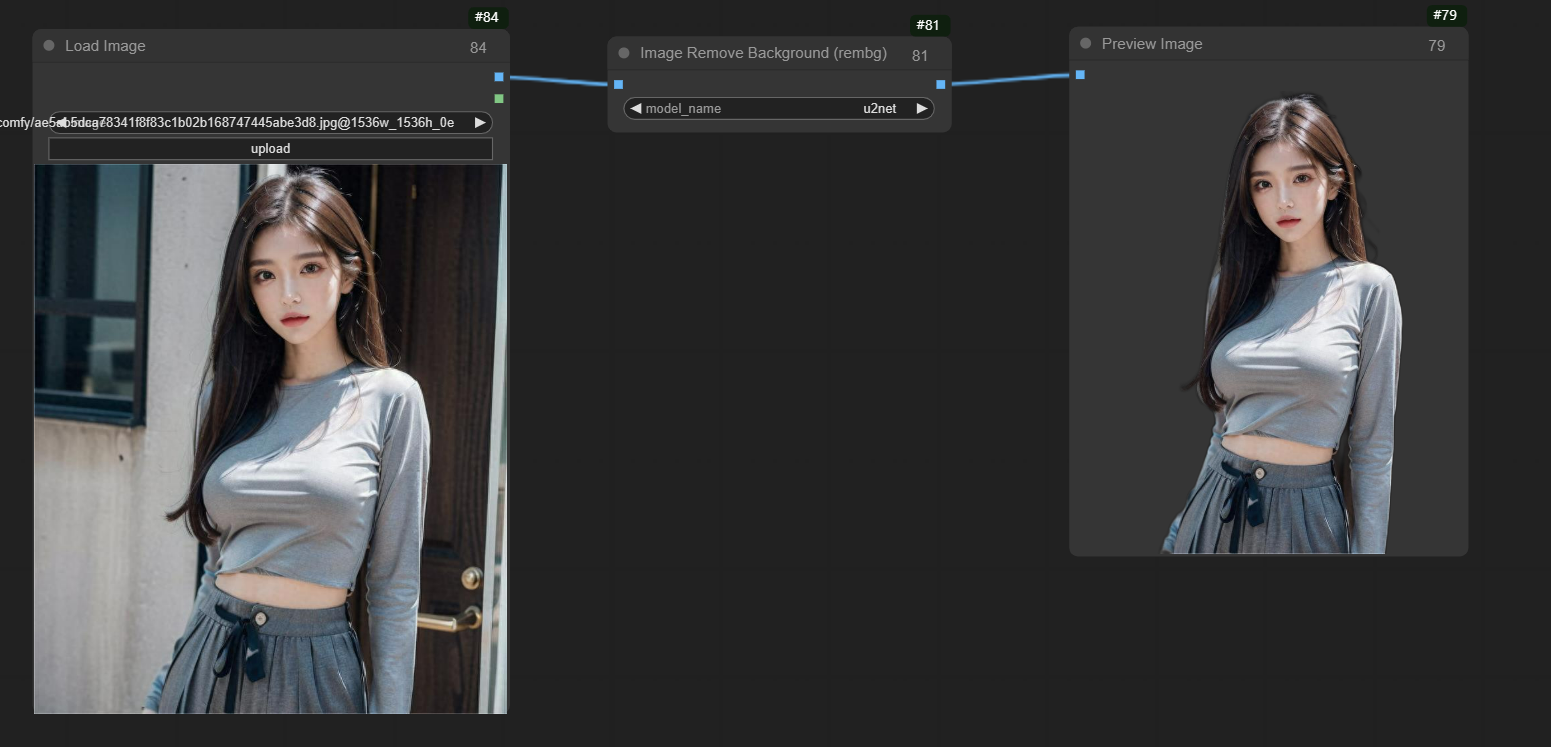
这里用到的是背景去除节点,节点官网:https://github.com/Loewen-Hob/rembg-comfyui-node-better
可以看到只需要一个节点就把背景去掉了,将此节点的输出接到之前的HED lines节点的输入上就可以了。
把他加到线条预处理之前就可以了
然后就是控制姿态了,加上openpose试一下:
把两个ControlNet串联后接入到采样器就可以啦,先看下生成效果:
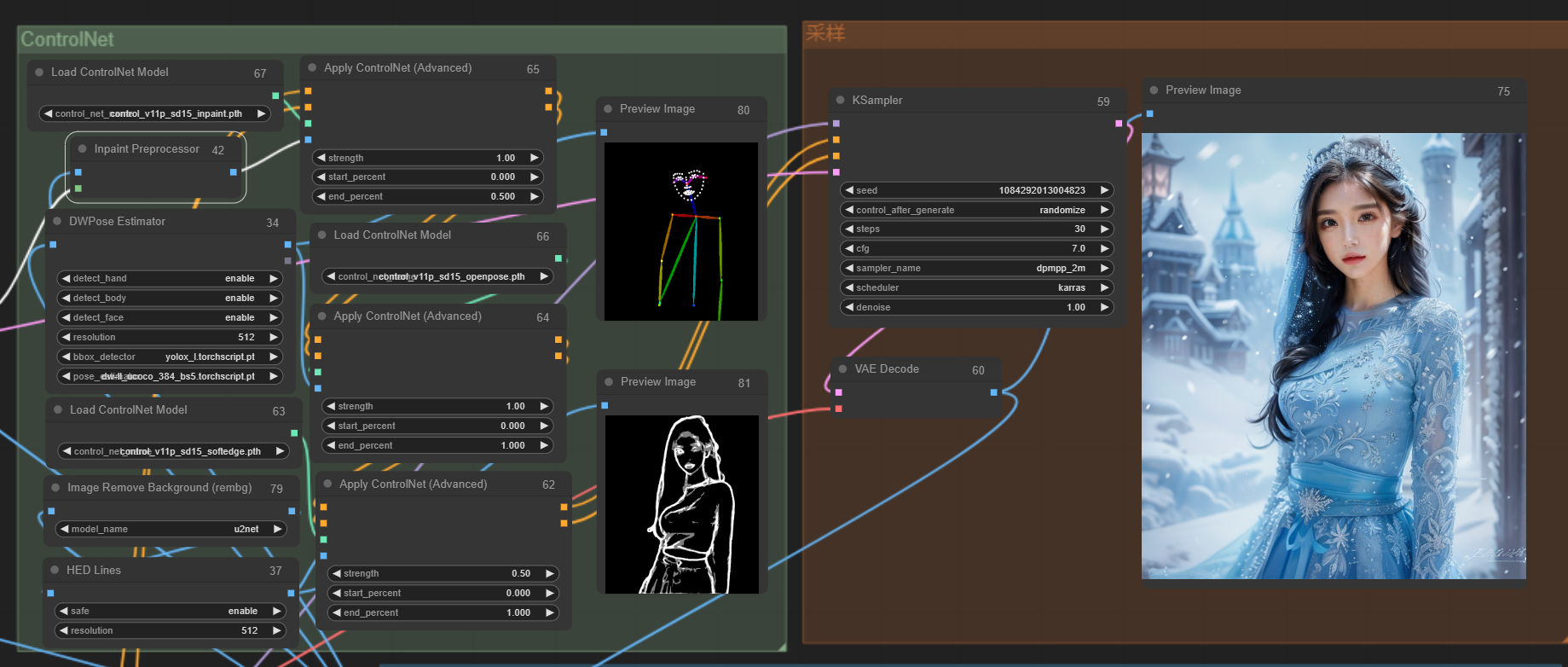
到这里,其实按需求来讲就已经ok了,但实际出图不是非常完美,因此我们再进行优化
4、修补
修图主要是对脸部边缘部分进行修复,使其融合的更自然,这里用到了ControlNet中的inpaint,我们只需要让其对蒙版和原图的衔接部位进行重绘即可,控制好幅度应该可行。
于是,ControlNet中仍然需要再串联一层inpaint:
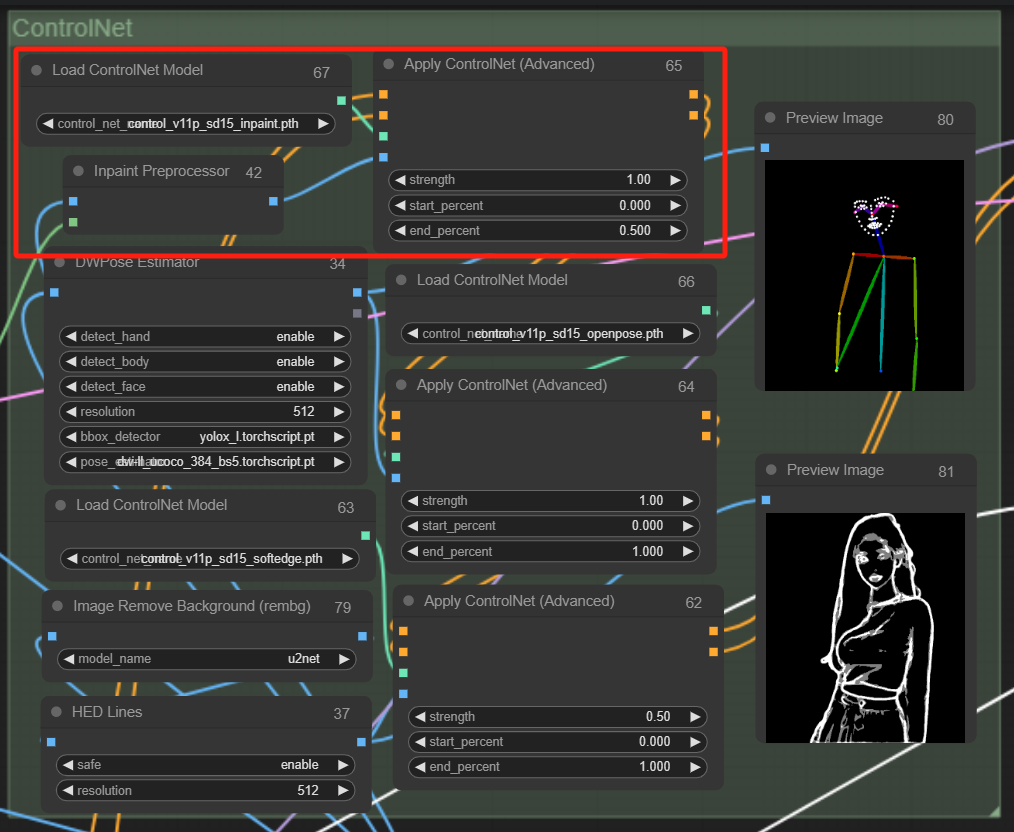
如上图,把inpaint串联上去,我们再看下效果吧:
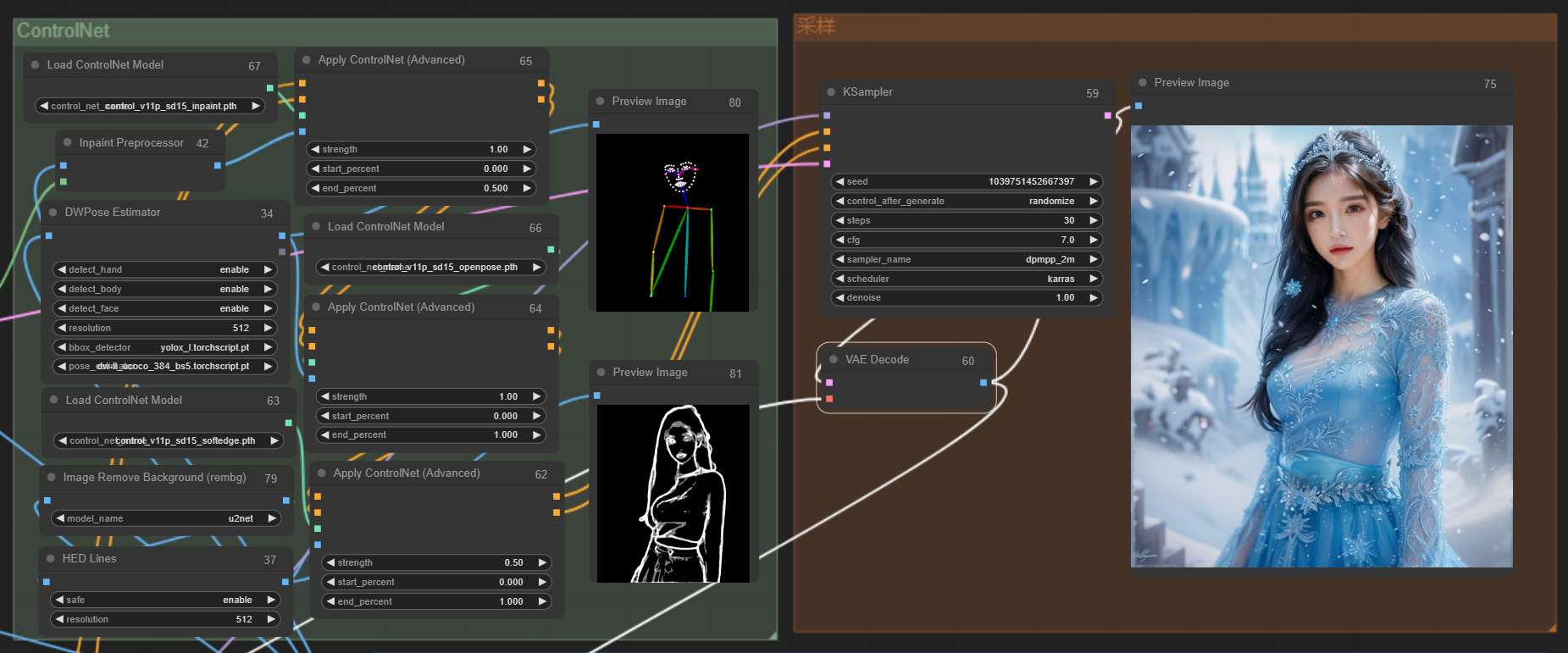
基本上完美还原了
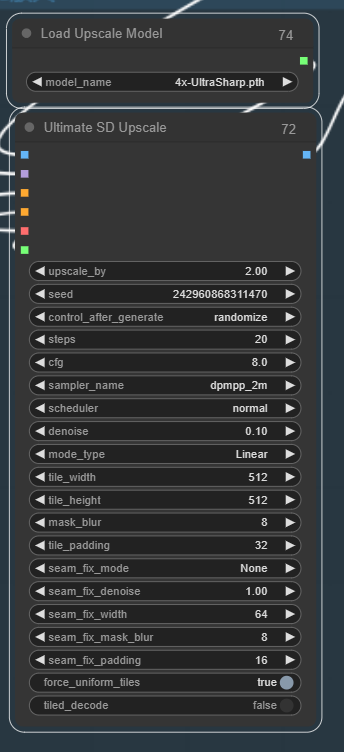
5、放大
考虑到原图像素可能一般,这里加一个放大功能,比较基础,就直接放流程图了
当然,这里用的sd放大会经过重采样会和原图略有区别,就和美颜后一样,这个可以通过调节降噪幅度自行调节到自己想要的程度。
最终出图效果:
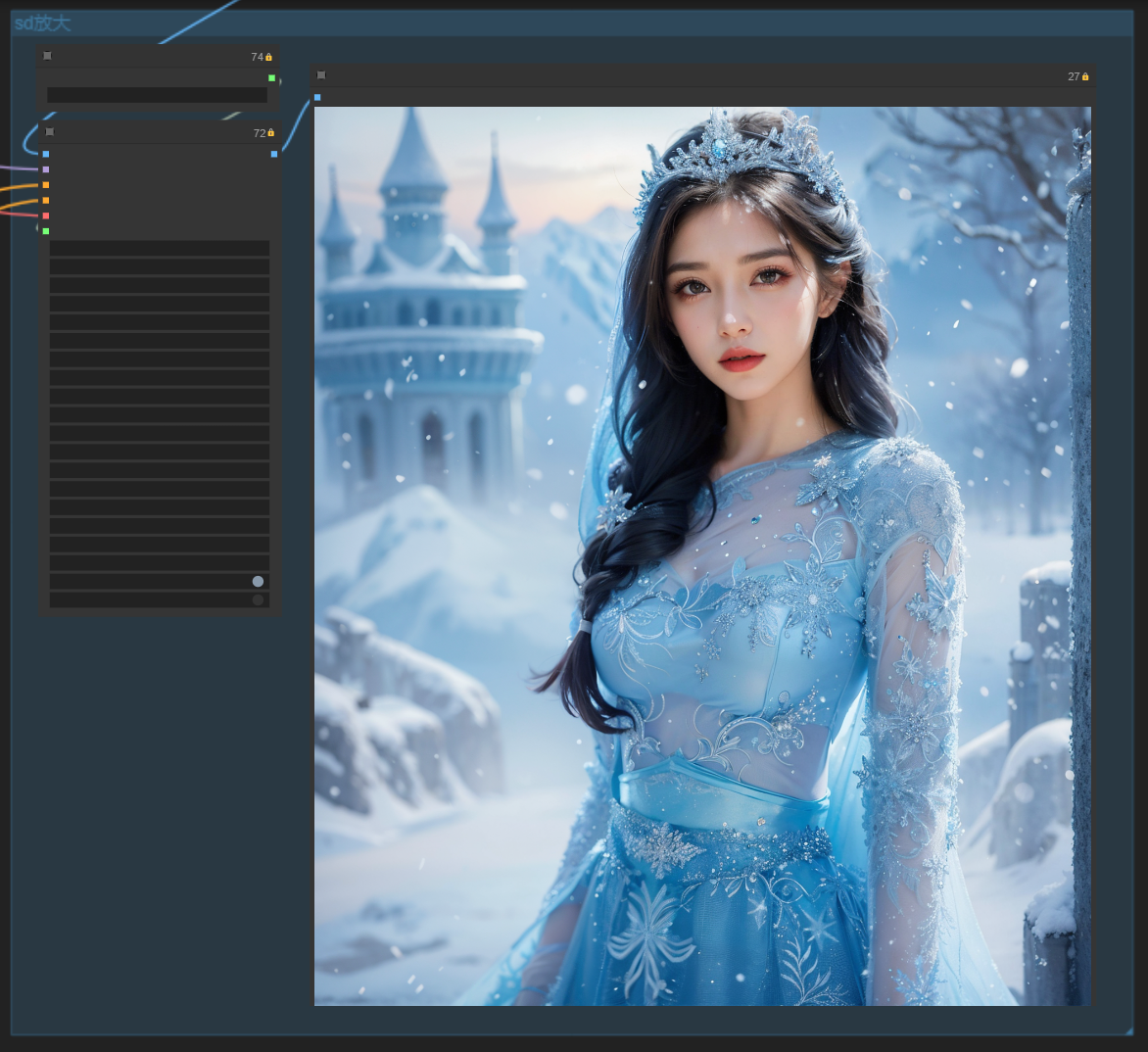
最后,流程图全貌
如果有启发可以点左下角有启发,让我知道哦;如果想互动可以点右下角写留言与我互动


🌟【全自动写真】🌟
想要保留人物脸部与姿势,但背景、风格随心变?这篇教程教你如何用AI轻松实现!✨
🔍 核心步骤:
1️⃣ 精准遮罩脸部,保留原貌
2️⃣ 利用ControlNet控制姿势,确保动作一致
3️⃣ 图生图+LoRA模型,打造不同风格
4️⃣ 细节优化,完美融合
💡 亮点:
📸 想了解更多?点击链接查看完整教程,解锁更多AI创作技巧!
👉 点我跳转
#AI写真 #AI创作 #全自动修图 #ControlNet #LoRA模型 #创意设计