背景: LAION数据集是什么数据集
LAION是一个在德国的非盈利性组织,主要从事大规模机器学习和数据管理研究,会公布一些开放的数据集,代码和机器学习模型。他们接受了Stability,Hugging face,Doodlebot等公司和一些实验室的资助。
LAION数据集是指LAION发布的以LAION开头命名的数据集,主要是图像-文本数据集
包括了:
- LAION-400M
- LAION5B
- LAION-coco
- LAION translated
- LAION5B High-Res
- LAION Aesthetics
- LAION-3D
LAION-400M和LAION5B 可以用于训练:
-
生成模型: 图像-文本生成模型,包括DALL-E这种自回归模型,GLIDE和Stable Diffusion这种扩散模型
-
使用contrastive losses的模型: 像CLIP
-
分类模型: zero-shot 分类模型
LAION-5B: 训练下一代图文模型的大规模开放数据集
- 标题: LAION-5B: An open large-scale dataset for training next generation image-text models
- 单位: laion.ai团队
- 链接: https://arxiv.org/abs/2210.06423
- 代码: 无代码
LAION-5B是一个5850亿对的图文数据,包括了2320亿对英文,2260亿对其他100种语言和127亿没有检测到语言的数据。
可以点击下面的链接访问这个数据集,官方提供了搜索。
clip-retrieval: https://rom1504.github.io/clip-retrieval/?back=https%3A%2F%2Fknn5.laion.ai&index=laion5B&useMclip=false
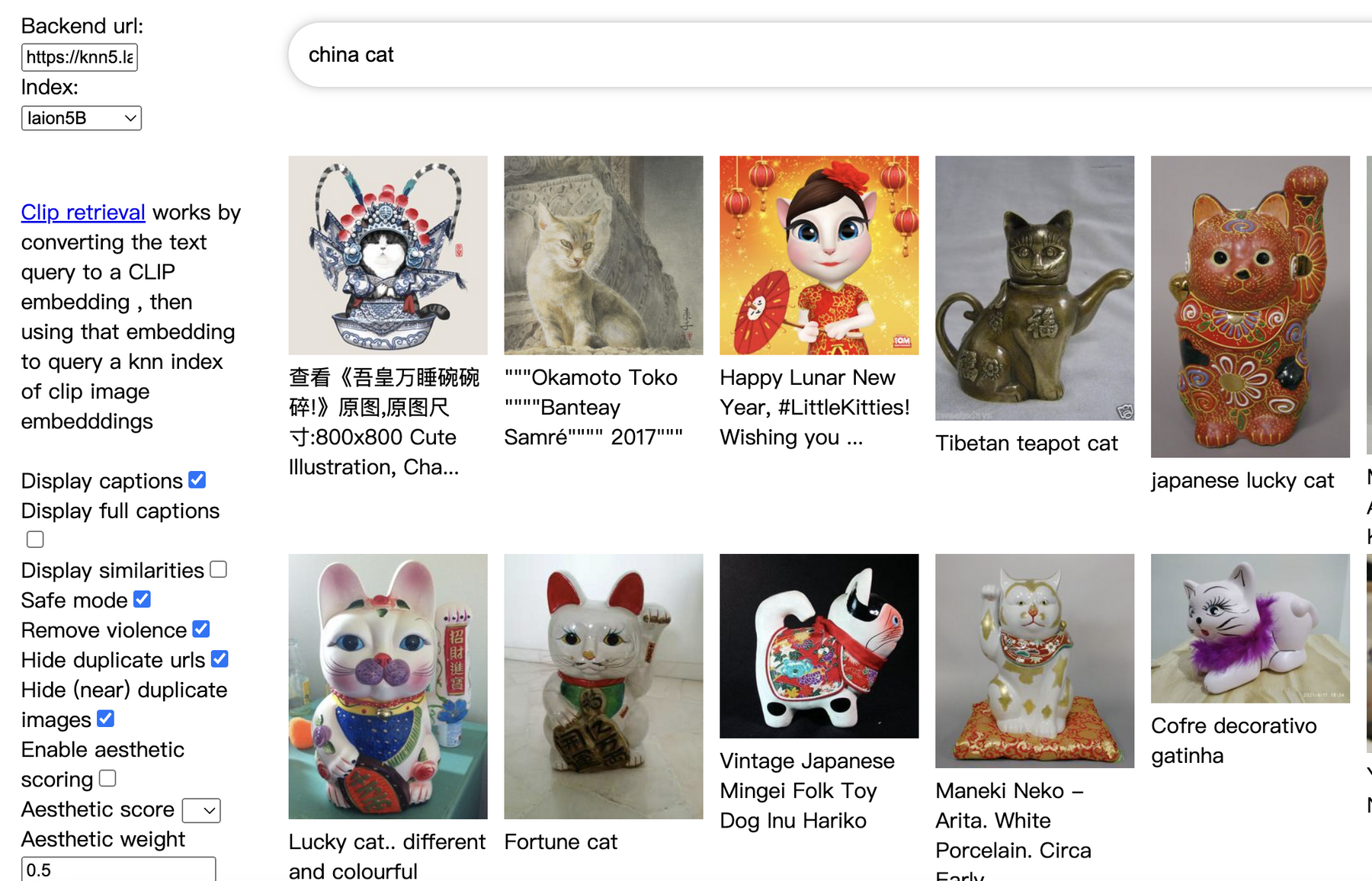
这个数据集包括下面的数据:
- 所有5850亿对图像的URL和元数据
- 一个KNN的索引,主要是支持在这个1.6TB大小的数据集快速搜索
- 一个Clip Vi-L/14 的图像embeddings (9TB)
- 一个基于这个数据集的图文检索demo,就是上面的clip-retrieval
- 基于这个数据集的安全标签(50GB)
- 这个数据集有水印的标记(50GB)
图像对有以下数据:
- 网址: 图片网址,覆盖了数百万个域名
- 文字说明,英文为 en,其他语言为 multi 和 nolang
- 宽度: 图片宽度
- 高度: 图片高度
- 语言: 使用 cld3计算
- 相似性: 文本和图像之间的余弦 相似度
- 水印: 基于https://github.com/LAION-AI/LAION-5B-WatermarkDetection模型检测的水印概率
- 不安全度: 基于https://github.com/LAION-AI/CLIP-based-NSFW-Detector模型检测的不安全度概率
图像抓取
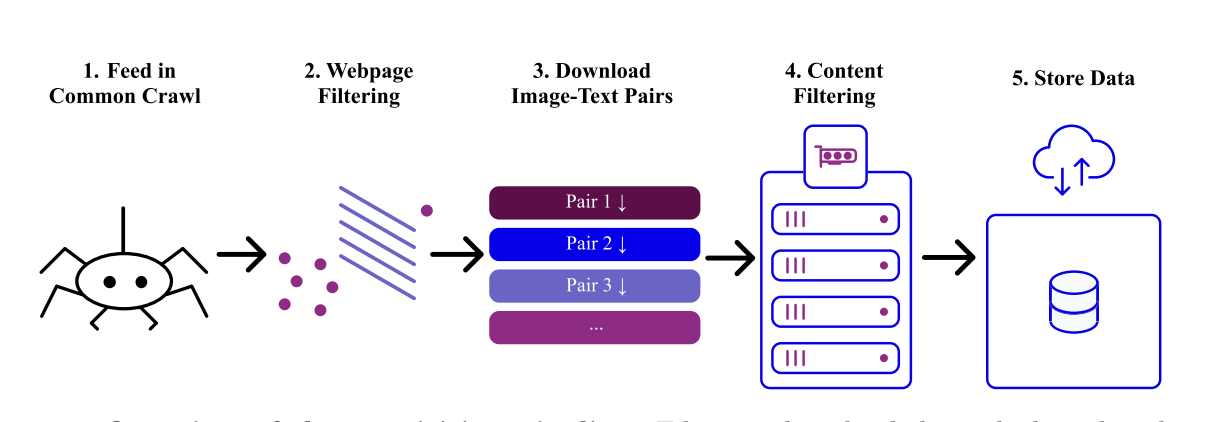
开发团队的工作流程如上图,开始是分布式爬虫,然后下载图片文字对,然后对内容进行分析处理,最后存储。
图像分别来自数百万个域名,然后用CLIP对图像文本对进行推理,计算图像和文本的相似度,相似度评分低的会删除,这个阈值英文为0.28,其他为0.26。
除了删除相似度低的图像文本对外,还会对一些不符合要求的图文对进行删除,包括了:
- 图像过小或过大,文本太小或太长
- 图像重复
- 一些非法内容
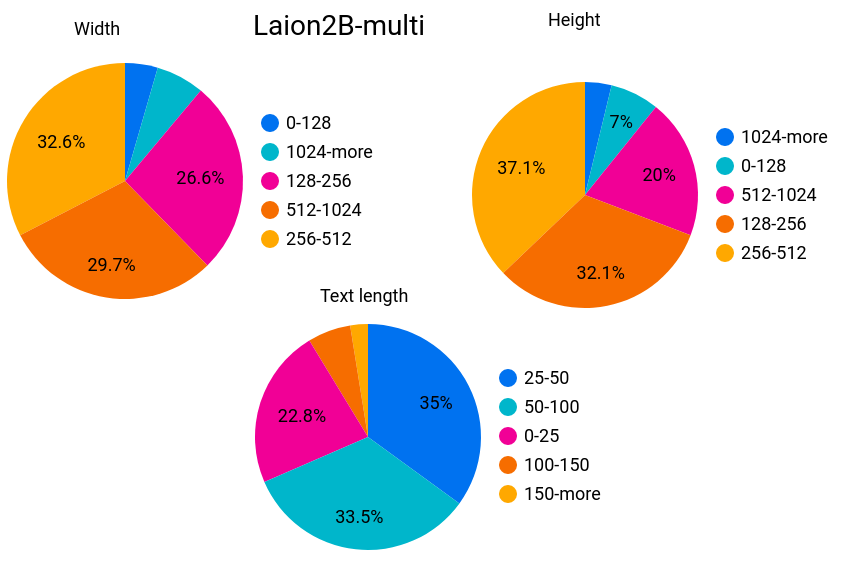
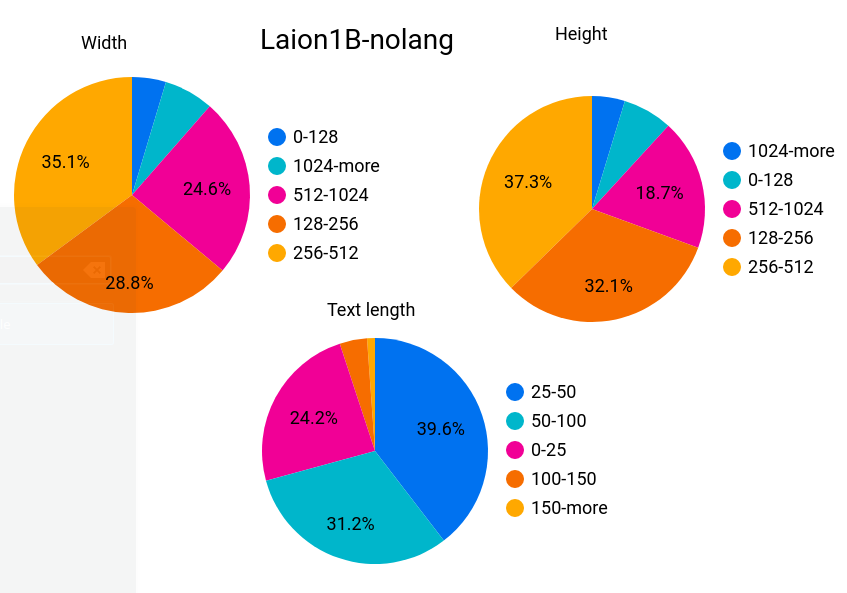
下面是所有数据集的样本统计:
英文样本统计

多语言样本
无语言样本
特殊处理
水印问题
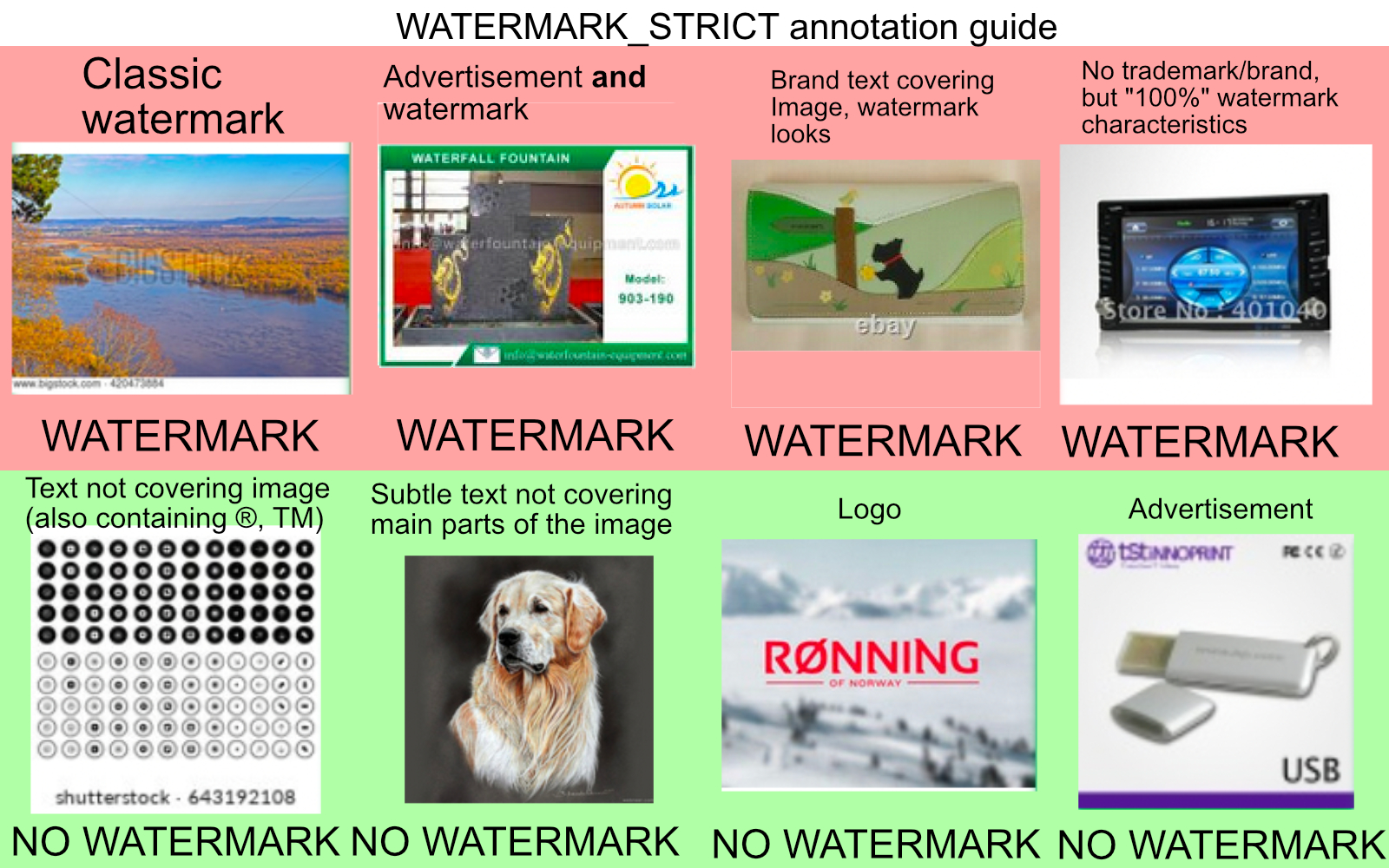
水印的图像是一个很大的问题,有人已经发现了生成的图像中会存在水印的情况。虽然开发团队已经处理了大部分的水印。
他们是用了9万个样本,45222个水印和44778个没有水印,训练了一个识别水印的模型来识别了所有的图片,有水印会被丢弃。但是有水印和无水印其实也存在模糊,比如底部有小透明文字的图片被一些人认为是水印,而另一些人则不这么认为,所以生成的图像是有可能有水印的。
水印模型已经开源了,链接:https://github.com/LAION-AI/watermark-detection
NSFW图像处理
NSFW是Not Safe For Work的缩写,主要指成人图像等不合适的内容。开发团队也训练了一个模型来识别这些内容,然后把识别到的图像都删除了。 训练集有3000个样本,分类器准确率为0.96。
模型和代码也开源了,链接: CLIP-based-NSFW-Detector
图像版权问题
论文中,有一个大家比较关心的点没有被提到,那就是来自这数百万个域名的5850亿个图像的版权是怎么样的。
可以肯定的是,开发者们使用爬虫爬取这些图像和后期处理时都没有考虑过版权。 很多创作者也通过公开的搜索工具搜到了自己的作品,作品被用来训练,这也给创作者们带来了一些被取代焦虑。
关于版权这个话题,后面一直会有争论,就看开发者们和创作者们怎么博弈了。就目前的数据集处理流程来讲,如果自己的作品不想被用来训练,只能在公布的时候打上水印,但这又是创作者们不想看到的。
参考资源:


🚀 探索下一代图文模型的新纪元! 🚀
你是否好奇如何训练出像DALL-E、Stable Diffusion这样的强大生成模型?🤔 这一切都离不开 LAION-5B —— 一个由德国非盈利组织LAION发布的 5850亿对图文数据集,涵盖了2320亿对英文数据和2260亿对其他100种语言的数据!🌍
📌 为什么LAION-5B如此重要?
🔍 数据集亮点:
💡 开发者们,准备好迎接挑战了吗?
访问数据集:LAION-5B数据集
论文链接:arXiv论文
🌟 LAION-5B 不仅是技术的突破,更是未来 AI生成内容 的基石。快来探索这个庞大的数据集,开启你的AI创新之旅吧!
#AI #机器学习 #图文生成 #LAION5B #数据集 #DALLE #StableDiffusion #CLIP #开源